Performance and Determinism
Background
A friend sent me a link to an ‘AI Ops’ company over the weekend asking me if I’d come across them. The product claims to do ‘continuous optimisation’, and it got me wondering why somebody would want such a thing?
Let’s explore the Rumsfeld Matrix
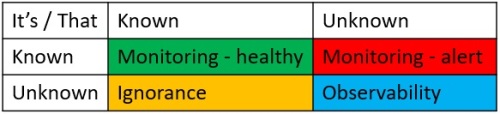
Known knowns
This is where we should be with monitoring. We know how the system is meant to perform, and we have monitors set up to alert us when performance strays outside of those expected parameters (at that point giving us a known unknown – we know that something is wrong, but the cause is yet to be determined).
Such known knowns are predicated on the notion that the performance of our system is deterministic. Expected things happen at the inputs, leading to expected things happening at the outputs, with a bunch of expected transformations happening in the middle.
Computers are superficially very amenable to determinism – that’s why they call it computer science. Modern systems might encompass vast complexity, but we can notionally reason about state at pretty much every layer of abstraction from the transistors all the way up to applications written in high level languages. We have at least the illusion of determinism.
Unknown unknowns
In ‘why do we need observability‘:
When environments are as complex as they are today, simply monitoring for known problems doesn’t address the growing number of new issues that arise. These new issues are “unknown unknowns,” meaning that without an observable system, you don’t know what is causing the problem and you don’t have a standard starting point/graph to find out.
This implies that we have determinism within a bounded context – that which we do understand; but that complexity keeps pushing us outside of those bounds. Our grip on determinism is slippery, and there will be times when we need some help to regain our grasp.
Unknown known
This is the intentional ignorance quadrant, and I think the target for the ‘AI Ops’ tool.
Yes, the dev team could spend a bunch of time figuring out how their app actually works. But that seems like a lot of hard work. And there’s a backlog of features to write. Much easier to buy a box of magic beans neural network to figure out where the constraints lie and come up with fixes.
This confronts the very real issue that getting a deterministic view of performance is hard, so of course people will be tempted to not bother or take shortcuts.
It’s easy to see why this is the case – I’ll provide a couple of examples:
Compilers work in mysterious ways
And so do modern CPUs.
In ‘The compiler will not save you‘ I’ve previously written about how a few different expressions of a completely trivial program that flashes Morse code on an LED result in entirely different object code. If our understanding of the compiler isn’t deterministic for a few dozen lines of C then we’re likely way out of luck (and our depth) with million line code bases.
Also for an embedded system like MSP430 (with its roots in TMS9900) we can reason about how op codes will flip bits in memory. But with modern architectures with their speculative execution and layered caches it gets much harder to know how long an instruction will take (and that’s the thing that lies at the heart of understanding performance).
Alex Blewitt’s QCon presentation Understanding CPU Microarchitecture for Performance[1] lays out some of the challenges to getting data in and out of a CPU for processing, and how things like cache misses (and cache line alignment) can impact performance.
Little changes can make big differences
Back when I ran the application server engineering team at a bank I was constantly being asked to ‘tune’ apps. Ultimately we set up a sub-team that did pretty much nothing but performance optimisation.
Most memorable to me was a customer facing reporting application that was sped up by 10,000x in the space of a few hours. I used Borland’s ServerTrace tool to profile the app, which quickly showed that a lot of time was spent connecting to the backend database. The developers had written their own connection pool class rather than using the connection pools built into the app server. Only that class didn’t actually pool connections. Amateurs 0, App Server Engineers 1. A single line of code changed, one additional config parameter to set up the connection pool, and the app was 30x faster, but it was still horribly slow – no wonder customers were complaining.
With the connection pooling resolved the next issue to become obvious was that the app was making a database call for every row of the report, with a typical report being hundreds to thousands of rows. This of course is what recordsets are for, and another trivial code change meant one database query per report, rather than one for every line of the report, which is MUCH faster.
The journey to understanding starts with the first step
If developers don’t look at the performance of their app(s) then they’re not going to be able to run small experiments to improve them. We have tools like profilers and tracers, we have practices like A/B testing, canary deployments and chaos engineering. But the existence of those tools and practices doesn’t fix anything, they have to be put to work.
Conclusion
Software is hard. Hardware is hard too. Understanding how a given piece of software works on a particular configuration of hardware is really hard. We can use tools to aid that understanding, but only if we care enough to pick them up and start trying. The market is now offering us a fresh batch of ‘AI’ tools that offer the promise of solving performance problems without the hard work of understanding, because the AI does the understanding for us. It might even work. It might just be a better use of our valuable time. But it’s unlikely to lead to an optimal outcome; and it seems in general that developer ignorance is the largest performance issue – so using tools as a crutch to not learning might be bad in the longer term.
Note
[1] The video of his talk to complement the slides is already available to QCon attendees, and will subsequently be opened to public viewing.
Filed under: operations | 1 Comment
Tags: determinism, monitoring, observability, performance, profiling, tuning
Subscribe
Recent Comments
Tim Coote on Ross Anderson RIP iain on Skiing in Espace Killy (Val… Chris Swan on Getting more from a British Ga… Murray Cowell on Getting more from a British Ga… JL on AI MacGuffin  Pinboard.in bookmarks
Pinboard.in bookmarks- syft: CLI tool and library for generating a Software Bill of Materials from container images and filesystems
- Jane Street is big. Like, really, really big
- Please Don’t Share Our Links on Mastodon: Here’s Why!
- Dairy Industry Forces Cancelation of Vegan Cheese
- Banksy on advertising
- RISC-V support in Android just got a big setback
- Raspberry Pi 5 vs Intel N100 mini PC comparison
- AI and problems of scale
- Medical cannabis to federal approval, recreational remains criminal
- The Net Promoter Score


Hey Chris
Very interesting – thanks.
From my perspective I take a slightly different categorization of the Rumsfeld Code:
Personally I believe that although conceptually, as you say, Known knowns should be the standard state for monitoring alerts, the problem is that in reality behavior is dependent upon neighbours and outside influences today. Consequently unless a System is closed loop, known knowns are less likely to exist today, meaning our thresholds (where they have been set) are either too chatty or not chatty enough.
So really, we are in state of monitoring that can be expressed as Known Unknowns, in other words we know that the combined state of CPU, Memory, Disk Writes and Transaction Demand (the Metrics Set) can cause a Known adverse behaviour issue…but we do not know what the parameters are for ‘this particular System’ right now…and what the parameters should be right now may not be the same parameters in 6 hours time. Additionally, the parameters for System 1 may not be the same for System 2 which may use identical components. So two AppServers for the same Application in a different datacenter/location or other may have a different operating window and parameter settings.
So this is a candidate for a set of AIOps techniques:
– establishing a baseline of behaviour (envelope) within a time period (operating window) for each given Metric source (i.e. CPU, Memory, Disk Writes, Transaction Demand) to surface real-time deviations from the normal envelop and operating window for each Metric
– cluster deviations of known Metrics Sets ((i.e. CPU AND Memory AND Disk Writes AND Transaction Demand) using some form of pre-defined recipe or, use unsupervised time/temporal clustering techniques or, use topographical techniques.
Unknown Unknowns are the norm for any non-closed loop system today where behaviour or Metrics Sets have not been previously experienced. In these cases, different techniques are necessary to ‘detect’ anaonalous behaviour…because of the following:
(a) we have not previously understood what is anomalous behaviour before customer facing experience is impacted and
(b) the ‘act’ of learning anomalous behaviour from historic telemetry in non-closed loop systems does not resolve the ‘detect unknowns’ use case. In other words, if you need to learn an unknown unknown before you can monitor for it, due to complexity and change, you are at risk of significant service interruptions that you have never experienced previously
(c) additionally, the more data stored in a big data warehouse (in order to have enough history to learn against) from increasingly diverse sources with no clear ontology between the data and data sources increases the cost of resolving actionable features and
(d) since the majority of telemetry produced (and consequently stored in the big data warehouse) lacks informational value (is noise) increases the costs and reduces the ability to resolve features and
(e) features that are resolved are sets of rules which are brittle – redundant when the ‘System’ is changed.
So the detection of Unknown Unknowns are a use case candidate for a different set of AIOps techniques, specifically designed to reduce the risk of business impact from constantly changing behaviour, that acts on streaming Metrics and non-Metrics (state/change/warning, etc.) telemetry messages to detect behavior that may not have been experienced previously:
– for Metrics sources, establish a baseline of behaviour (envelope) within a time period (operating window) for each given Metric source (i.e. CPU, Memory, Disk Writes, Transaction Demand) to surface real-time deviations from the normal envelop and operating window for each Metric to produce ‘Alerts’ for clustering (basically producing a ‘filtered Alert set’ (surfacing signal from noise)
– for non Metrics sourced Alerts (changes, states, logs, etc.), just like for Metrics, since >90% of the telemetry produced lacks informational value (is noise) we first need to apply AIOps techniques to surface signal from noise. (In old rules based systems, this might be ‘don’t show this Alert until it’s happened 5 times’ or, ‘filter anything non-critical’. The problem is, rules are not scalable and, in modern environments non-Metrics telemetry lacks reliable Severity ratings). So the AIOps technique needs to offer an unsupervised method of categorizing telemetry in real-time regardless of source and type in order to filter low informational value telemetry and give the detection analytics a better chance of resolving features
– Detection analytics techniques applied to any non Metrics sourced Alerts (changes, states, logs, etc.) and Metrics Alerts, using unsupervised and semi-supervised streaming analytics clustering techniques like time/temporal clustering techniques or, use topographical techniques
Of course, these AIOps techniques are applied to the incoming Telemetry. There are other AIOps use cases to be applied to the workflow element of the “Operations and Support” processes.