July 2026
Pupdate
The whole of July has been hot and sunny (more on that later), so quite often the boys have been having an early morning walk in the shade of the woods before it gets too hot.

The apple tree seems particularly bountiful this year, so they’ve both been enjoying the windfalls (particularly Milo).
Bath
$daughter0 has completed her degree in Chemistry with Management, so we returned to Bath for the graduation ceremony and some celebratory dinners and drinks.

The ceremony was in Bath Abbey, which is right in the heart of the city. It was a fantastic place for the event, and it was great to see so many (former) students around the city in their gowns.
Dinner in Raphael was fantastic (as it always is), and that’s one of the places that will likely draw us back to Bath even though we won’t have a family connection there any more.
EMFcamp
Since I was already in the South-West of England I didn’t return home from Bath, and instead headed to Bristol to pick up a camper van called ‘Blubelle‘ that I’d found on Quirky Campers. From there it was a short trip to the Eastnor Castle site, and I picked up $son0 from Bristol Parkway station on the way. Not spending many hours on the motorway in a huge unfamiliar vehicle turned out to be a much better way to kick things off, and might well be part of future plans.

This was my 4th EMFcamp, and it’s become one of my favourite things to do every other year. Getting tickets this year was harder than ever, and I’m very grateful to my friends who helped me out with that :)
Running later in the year offered the possibility of better weather; but the reality was that we caught the run on of the third 2026 heat wave making it dry and hot throughout. So no need for wellies and waterproofs :) The weather made for a slightly different experience versus previous events, with fewer people cramming into the big tents for presentations and much more just hanging out and chatting.

I spent most of my waking hours in talks or hanging out with friends. We were a little more organised this time, and had a village for ‘Homebrew, Historical and Retro Computing’; though we likely spent more time together at the bar than in our official location. Once again a highlight for me was the ‘whisky leaks’ event run by the Milliways village, and I took along a decent bottle from the Scotch Malt Whisky Society (SMWS), It was scheduled to run from 2000-2200, and I found myself calling it quits sometime after 0100 :0
Volunteering
I signed up for volunteering in ’24, but too late to find a shift that I could do. That meant I didn’t have early access to tickets for ’26. So when volunteering opened up this time around I grabbed a couple of shifts in the hope of securing tickets for ’28.
I did a stint as ‘herald’ for Stage B, which is a bit like being a conference track host, but without all the months spent finding speakers.

I also did a 2h shift at the bar. It was Sunday afternoon, and so not too busy; though sadly we’d run dry of many things :(

Sadly I didn’t get to use either of my Meal Token’s, as dinner didn’t start until 1930, and I was hungry (for a burger) at 1830 (and joined some friends for a bite to eat and a chat before the screening of The Princess Bride, which I’d never seen before).
New TV
We (finally) moved back in to our bedroom after getting a new en-suite, and it quickly became obvious that the old 27″ TV didn’t really fit in properly. So I looked up what size TV we should have and it came out at a somewhat ridiculous 75″.
We ended up compromising on 50″, which I think fits pretty well.
I had a nice set picked out, but $wife objected to it being too thick (at something like 74mm). It turned out that the #1 aesthetic driver was ‘as thin as possible’, and that took me to the Samsung QN90F, which is 26.9mm thick!
In the past I’ve avoided 4K and ‘smart’ TVs, but those things seem to be pretty much unavoidable now, so I’ve simply not connected it to the network or activated any services. It works just fine with digital terrestrial channels and a Fire Stick[1].
TV mount
A very thin TV needs a very thin TV mount. Samsung make one, the ‘slim fit wall mount‘, and charge silly money for it. Thankfully there seem to be plenty of clones on Amazon, and I went for the VIVO Micro-Gap Flat TV Wall Mount, which is £100 cheaper than the sticker price for the official one. Amazon wouldn’t let me generate an affiliate link for that, because apparently it’s a ‘frequently returned item’; but I’m very happy with mine, as the build quality seems excellent.
The tricky bit is that you’re supposed to ensure that both mounting plates get secured to wall studs (rather than just plasterboard)[2]. That’s helped by those plates having numerous holes, but I needed a stud finder (affiliate link) to locate wood to secure them to. For each side I was able to put 2 screws into wood, and the other 2 went into the supplied Fischer DuoPower plugs (which are excellent).

I’m happy with the result. The TV looks good from the side, and it looks great from the front when it’s powered up :)
The hunt for a new scooter
Last month brought (More) Scooter Bother, with the engine on my Vespa ET2 losing compression (again). I wasn’t in the mood for another engine rebuild.
But… finding a replacement has proven to be more difficult than expected. When I had to rebuild the engine last year there was a plentiful supply of Piaggio 1 Active electric scooters, with new ones typically £1899 (due to government incentives) and (lightly) used around £1199. That supply has since dried up, but also reviews suggest that they’re not especially reliable (and maybe a smidge underpowered).
I took a look at a 125cc Vespa ET4, which has the advantage of being the same size and shape as my ET2 so accessories could be ported over. But there was something wrong with the immobiliser, and it didn’t seem to go past 30mph (where it should easily do 60mph).
Then I found that Honda have got a serious entry into the e-scooter market with the CUV e:, but because it’s so new the cheapest examples are selling for £3299; and that’s a bit rich for the small mileage I do (mostly up and down to the station).
So… after maybe too much time trying to find a new(er) scooter I’ve decided it’s probably just as easy to fix my old one (again).
A/C
It’s been a VERY hot and sunny July. I don’t know whether we’re officially on heatwave 7, or whether it’s actually heatwave 3D because this one just kept rolling on.
When the heat pump was installed $wife complained that the unit over her dressing table was ugly. That view changed the first time she needed to get ready on a (too) hot day. And now the heat pump is basically the best thing we ever bought. Being able to keep the temperature in the low 20s indoors when it’s mid 30s outside is a good thing :)
I finally got around to attaching the head units to their mobile app (and the devices network on my WiFi), which means that I now have data on power consumption etc.
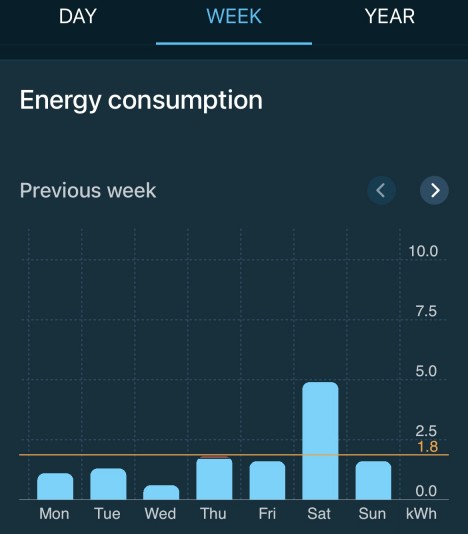
But… the app isn’t great (compared to my solar inverter app), so I can only see charts for this week and last week rather than going back further. Somebody will hopefully be along in the comments to tell me how to get better data export via Home Assistant or similar.
What I can see is that a heavy day of A/C is using around 8kWh whilst the solar panels are making more than 3x that, so I’m sacrificing about £1.20 in export tariff to keep cool, which seems worth it :)
Solar diary
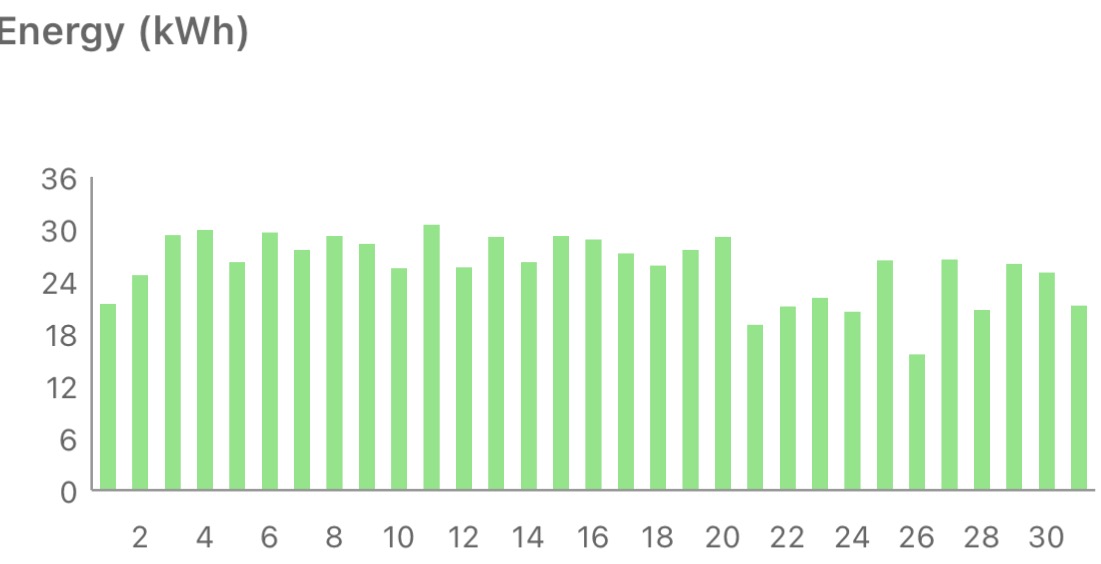
Unusually hot came with unusually sunny, making July 2026 the sunniest month since I got the system installed, (just) beating the previous record of 794.9kWh set in June 2023. At one stage I thought it might exceed 800kWh for the month, but the final tally was just short of that mark.
Notes
[1] Yeah – I know I’m selling myself out to Amazon with the Fire stick, but I already did that (many times over). I just don’t want to sell myself (again) to Samsung and…
[2] This, along with some shelves I needed to put up sent me down something of a YouTube rabbit hole on various options to secure things to plasterboard. Fischer DuoPower plugs are really good, and the Duotec toggles (affiliate links) are even better. But ultimately a better mounting will just pull a bigger chunk of plasterboard out of the wall, leaving a larger hole to be repaired :0
Filed under: Uncategorized | Leave a Comment
Brewster’s Trillions
TL;DR
The AI infrastructure bubble has reached a point where companies just can’t actually spent all the money they might (notionally) have allocated. There might be money on a balance sheet somewhere, but good luck exchanging it for actual GPUs, or HVAC, or HVAC installers, or… When the sums of money get large enough it turns out that it’s difficult to actually spend it. That was the setup for George Barr McCutcheon’s 1902 novel ‘Brewster’s Millions‘ (and the multitude of film adaptations). Of course the sums of money now are MUCH, MUCH, BIGGER, which is why I’ve taken to calling this Brewster’s Trillions (or the Brewster’s Trillions problem).
Brewster’s Millions
The plot device of the book is that Montgomery Brewster must spend $1M within a year in order to inherit a much larger sum (timing and values vary in the films). This turns out to be more difficult that it initially seems, as he has to finish with no assets, and there are limitations on gifts, donations etc.
Various comedy sub plots get built around the notion that when you have lots of money, it’s hard to actually spent it all, especially if you’re working to a deadline.
AI spending
This chart from Fin Moorhouse got lots of attention a few months back:
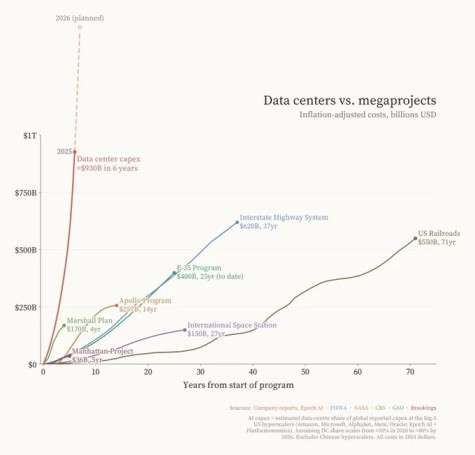
But news is starting to come in that stuff planned for 2026 isn’t actually happening[1]. It turns out that when you buy ALL the stuff, whether that’s land for data centres, or GPUs to run in them, or HVACs to keep them cool, or energy to power all that, or contractors to do the installation work and maintenance; you can’t just show up with more money and buy more of the same. That’s because the earlier buying has exhausted supply, and whilst economics 1.01 will kick in and inflate prices (viz RAM[2]) a point is quickly reached where certain things can’t be bought at any price. For much of the AI supply chain we’ve already passed that point. Companies that locked in deals early might continue to get what’s being made, and the makers might do their best to expand capacity. But all that takes time, and so the rate of spending has to bend.
Stein’s Law is now in effect:
If something cannot go on forever, it will stop.
Notes
[1] 35-50% of planned AI data centres are behind schedule
[2] Tom’s Hardware now has a headline category for RAM Shortage
Filed under: Uncategorized | 2 Comments
June 2026
Pupdate
The start of the month saw the raspberries coming out on the bushes in our garden, so Milo (in particular) got busy harvesting what he could reach (and barking at any birds that dared to come nearby).

Max seems to be back to normal after his back trouble last month, and Milo has finished his chemo and had a scan that confirmed he’s still in remission :)
Berlin
Google’s I/O Connect rolled around again, and I went to Berlin for that and the European GDE Summit. It was great to hang out with the usual suspects.
Berlin was VERY HOT (mid 30s C), though that was no different from home as a ‘heat dome’ covered much of Europe. Berlin architecture is perhaps better suited to the heat, and it was maybe a little less humid than in England.

In addition to hanging out with the Google crowd I did the now customary Berlin ex-pats get together, which was a lovely dinner outdoors at Cafe am Neuen See.
The Bohemians
I booked to see Queen tribute act The Bohemians without paying proper attention to my schedule, resulting in something of a rush back from Berlin fighting against (delayed) planes, trains, and automobiles a much longer scooter trip than I’m used to (with far too many summer evening insects trying to get into my face).

It was worth it though. I got to the venue just in time for dinner before the kitchen closed, and the band was amazing. It was a lot of fun to rock along to familiar songs with a table of friends and a room full of fellow aficionados.
(More) Scooter bother
Getting my Vespa home was fine until it wasn’t. I’d been zipping along quite happily until the edge of town when it suddenly cut out. It started up again, and I hoped to limp home, but after a few more stalls I decided to pause and let things cool down. That was maybe a mistake, as my next attempt to start resulted in the sad sound of no compression :(
I think I’m now in the market for a new (or at least different) scooter, as I’m kind of sick of pushing this one home and having to mend it.
Solar Diary
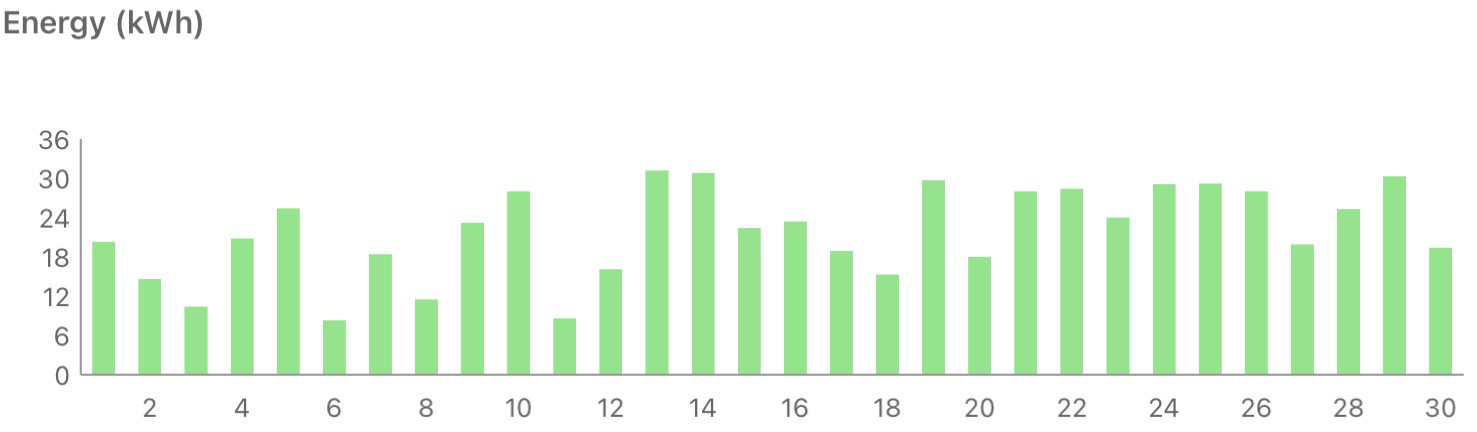
The worst June yet, with a little less production than May :( It was rainy and overcast for much of the start of the month, and then too hot towards the end of the month.
Filed under: monthly_update | Leave a Comment
Tags: google, pupdate, solar, GDE, Miniature Dachshund, Queen, Berlin, Vespa, The Bohemians, scooter
Miell’s Law and Token Budgets
TL;DR
Conway’s Law tells us that organisations create systems that mirror their communication systems. Jamie Dobson coin’s ‘Miell’s Law’ in a post about the work of our mutual friend (and his colleague) Ian Miell in his forthcoming book ‘Follow the Money‘:
Organisations that design systems are constrained to produce systems that reflect the financial structures and incentives of those organisations.
We can all imagine how that applied to organisations we know from the past. But I think it’s about to be massively amplified by how money gets converted into large language model (LLM) tokens, and how those tokens get doled out to those using them.
The free ride is over
Since the arrival of ChatGPT we’ve all been able to use LLMs and the various coding assistants and harnesses built upon them at no/low cost. Chatbot type interfaces are still generally free to use, and subscriptions have been selling the underlying tokens at (fractions of) pennies on the dollar. Many commentators have compared it to the early days of Uber, where rides were being subsidised by investor capital in order to grow market share and build a ‘winner takes all’ monopolistic network.
Despite something like $1.4Tn in infrastructure investment we find ourselves in a place where there simply isn’t sufficient supply for LLM inference to satisfy the insatiable demand. But as a wise colleague once said – ‘there’s infinite demand for free stuff’.
The first cracks showed with Anthropic changing the terms for Claude subscriptions so that they couldn’t be used for autonomous agents such as OpenClaw.
Next came Google, with ‘Changes to Gemini model access and limits‘.
But the move that’s likely to hit the hardest is GitHub CoPilot’s changes that took effect at the start of this week (Mon 1 Jun). Folk that were paying $tens for a subscription that burned $thousands in tokens are about to be hit with the full bill. There’s going to be some bill shock at the end of the month, and some very angry CFOs.
Who gets the tokens (and how many)?
Companies are reacting to the pricing changes by introducing token limits. Simon Willison has a good analysis of Uber introducing a flat cap of $1500 per tool per user (and there’s a company that knows only too well what an ‘Uber moment’ looks like).
I’m hearing reports from elsewhere that graduated limits are being introduced. Distinguished Engineers get unlimited tokens and access to the best new models. Entry level folk get a tiny budget and may also be constrained to older/cheaper/less potent models. That’s obviously going to magnify the impact of the power structure on productivity – Miell’s Law in action. Of course a Distinguished Engineer can be super productive with their awesome experience and a huge token budget on leading models. But do these orgs really want to force their early career folk (assuming they’re still hiring any) to be less productive? Have HR even had a say in this? I can imagine some spectacular fodder for future industrial tribunals.
The days of ‘tokenmaxxing’ are likely over, with Amazon shutting down its token leaderboard. Clearly they created an incentive structure that wasn’t properly aligned with what the company actually needs/wants.
Jensen Huang has stated that he wants Nvidia engineers to use AI tokens worth half their annual salary. But of course he has GPUs to sell us (or the services supplying us), which might still put him on team tokenmaxxing. I’m also left wondering if that March budget of $250k for an engineer with a $500k salary turns into a June budget of $Millions, or if even Nvidia engineers suddenly have less to work with?
What’s fixed and what’s variable (and has any of this been budgeted)?
Finance folk will often refer to fixed costs and variable costs; and headcount often lies awkwardly in the middle (depending on how easy it might be to hire and fire, which in turn can depend a lot on local labour laws).
From a Conway/Miell’s Law perspective the good old org chart reflects a whole bunch of budget that’s been allocated where the people below the apex have almost no discretion on changing things.
We now get to overlay token allocations into that org chart, and discover how much discretion is associated with that? I’d speculate that approximately zero organisations going through their FY26/27 budget planning had an accurate notion of 26H2 token costs or the allocations they’ll flow to, which means everybody is now making it up as they go along (or ‘being agile’ if you prefer).
Conclusion
AI coding assistants have been seen to boost productivity (especially for knowledgeable people who are good at articulating what they want); and that productivity boost was a ‘no brainer’ when the cost was (approximately) free. But the costs are shooting up, in part to ensure that demand is constrained to meet limit supply. That’s forcing organisation to think about how they allocate tokens, which is introducing a new dimension of financially structures and incentives. Miell’s Law might only have just been coined, but it’s going to be an important thing to consider as the post free ride budgets get figured out.
Update 9 Jun 2026 – I like this post (the Hello, World! section) where Ken Corless talks about how they’re managing token budgets at Deloitte.
Filed under: technology | Leave a Comment
Tags: AI, amazon, budget, ChatGPT, Claude, coding, Conway, Conway's law, CoPilot, finance, Gemini, google, HR, Jenson Huang, Miell, Miell's law, NVidia, tokenmaxxing, tokens, Uber
May 2026
Pupdate
It was Milo’s 5th birthday on the 12th, which meant a post about how he’s getting on.

Sadly Max has also needed to visit the vets, with (we think) back ache, which might be the dreaded Intervertebral Disc Disease (IVDD). He’s been on reduced activity, so shorter walks, but thankfully seems pretty much back to normal after some painkillers and anti-inflamatory treatment.
Tech stuff
2.5gb ethernet
Having accumulated a handful of things that have 2.5gbe ports I’ve taken the plunge and bought some newer switches to connect them. They were a little fiddly to set up, hence the VLANs on Sodola managed switches post; and I notice that newer firmware has modified that config page a little.
Of course I couldn’t stop at just the things that already had 2.5gbe, so I’ve added new interfaces to my NAS and VMware box, as (aside from my desktop) they’re the things that create the most traffic copying files back and forth. For the NAS I got a USB adapter with an RTL8156 that works with these drivers, and for the VMware box a DollaTek M.2 card (affiliate link) that works with the Realtek Network Driver for ESXi. Everything seems to be reporting around 2.35GB/s on iperf3 :)
MacBook Neo
I had a (dated at the time) MacBook during my time at Cohesive over a decade ago for when I needed a Mac, but I never got along with it. But… I’ve been impressed with the reviews of the MacBook Neo, and it would be handy to have something that can (occasionally) run Xcode. So I got an Indigo 512GB one.
Early signs are very good (despite only 8GB RAM). It’s perfectly capable of running multiple browser and Ghostty tabs, which is the main thing I need from a laptop. Battery life is amazing, and it goes for days between charges. Better integration with my iPhone, iPad and iMessage seems very useful, so overall I’m impressed :) I’m going to see how I get on with it in my travel bag instead of my ThinkPad.
The only time it seems sluggish is when using Chrome. Task switching to Chrome takes an age, as does opening a new tab. I suspect Chrome might be a massive memory hog, and provokes a bunch of swap file activity.
Scooter fettling
My Vespa started cutting out when accelerating from a standstill, and a conversation with Gemini suggested that I needed a new carburettor (and maybe bigger jets). The new carb is in, and after some trial and error it’s running with the factory jet :/ But… at least it seems to be running properly again.
Eyes
I’m done with having to administer drops multiple times a day, and my ocular pressures are back to normal – yay :) I also seem to have found the right glasses for computer work (+0.75) and reading (+1.5). The light sensitivity I was experiencing at the end of last month has gone, so I’m probably not in the market for new sunglasses. Though there are times when I feel some varifocals might be useful (even if the ‘distance’ lens is planar).
But… my most recent check identified that I’m developing a ‘secondary cataract’ (aka Posterior capsule opacification (PCO)), which is going to need YAG laser treatment in a couple of months.
Solar Diary
The first part of May felt like it was making up for the lack of April showers, but that gave way to a week long heatwave (and lots of sunshine). The effect of heat on production can be seen with a ~5% drop between the 22nd (29.1kWh) and 24th (27.6kWh), though subsequent days bounced back up to 29.1kWh (and then 29.4kWh) even though it remained hot.
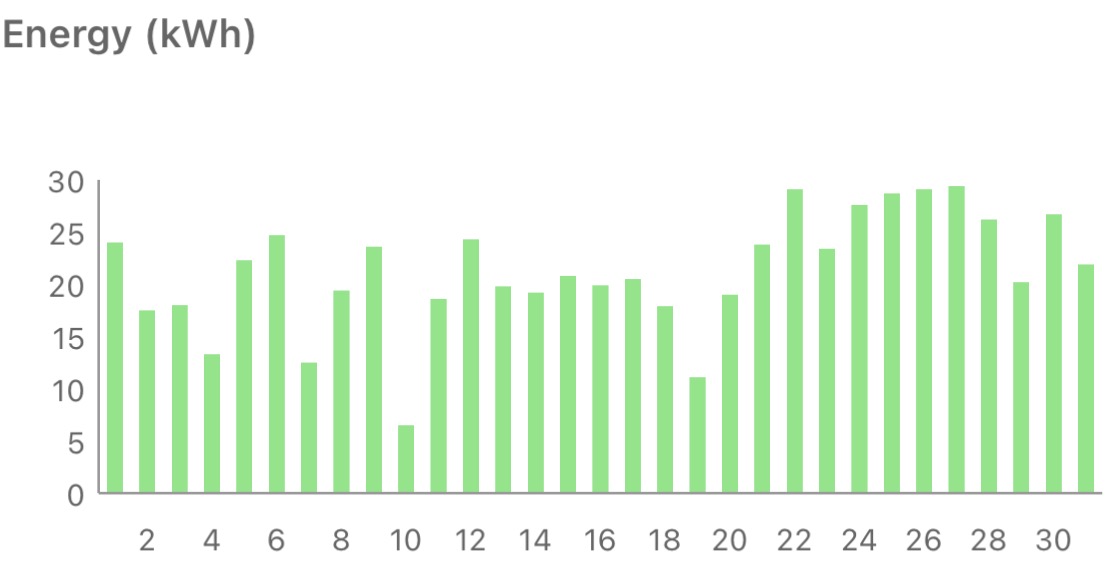
Total production was a little short on the best May yet (2023), but better than the last couple of years.
Filed under: monthly_update, technology | Leave a Comment
Tags: 2.5gb, 2.5gbe, cataract, dachshund, ethernet, MacBook, Miniature Dachshund, Neo, networking, Realtek, solar, Vespa
Milo cancer diary part 23 – Five
Milo is five today, which he’s mostly celebrating by snoozing on the office sofa behind me.

He’s nearing the end of his fourth (modified) CHOP protocol, with just over 4 weeks and 3 more vet visits to go.
Since going into remission at the start of the year things have proceeded mostly uneventfully, which is how we like it. The one hiccup has been when the vet couldn’t get a line in for Vincristine. A little manoeuvring was needed around winter half term and Easter holidays; but that was due to vet availability rather than anything going on with Milo.
ManyPets have been prompt with payments, with everything up to date at time of writing. There should be enough to get him to the end of this protocol, but the follow up scan will likely tip things past the annual policy limit before it resets in August. Hopefully he gets another extended remission to enjoy the summer.
Past parts:
1. diagnosis and initial treatment
Filed under: MiloCancerDiary | Leave a Comment
Tags: birthday, cancer, chemo, chemotherapy, CHOP, insurance, lymphoma, Miniature Dachshund, remission
VLANs on Sodola managed switches
TL;DR
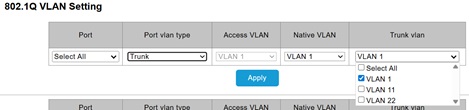
There’s an aspect to the web user interface of Sodola switches that’s far from obvious, and not documented :/ When setting up trunk ports it’s necessary to select all the VLANs that will be carried, and the default is only to select VLAN 1.
Background
I’m starting to accumulate a small selection of things with 2.5gbe ports – my GL.iNet Flint 2 router, the motherboard in my silent desktop, and the Zyxel NWA50AX Pro access point I got to complement the Flint 2 (running OpenWrt naturally). It wasn’t practical to plug everything directly into the Flint 2, so I needed some new switches.
With some building work going on in the house the physical trunk running between the coat cupboard containing the router and my office with the PC and access point was open, so I took the opportunity to drop a fiber SFP cable (affiliate link) to create a 10G network trunk. I just needed a pair of switches to light up that link, and I went for a Sodola 6 port (SL902-SWTGW124AS) and 9 port (SL902-SWTGW218AS) [affiliate links] to replace 5 port and 8 port TP-Link gigabit switches.
VLANs
My VLANs setup is fairly straightforward with the following 802.1Q tags:
- 1 – Default home network
- 11 – Guest network (mainly used for WiFi)
- 22 – Devices network
The 6 port switch needed tag 22 to emerge on the wire for the network dongle in my Growatt inverter[1]. Here’s the config I ended up with:

This wasn’t working initially because the default when creating a trunk is to select just VLAN 1, and the checkboxes to select all (or pick specific tags) wasn’t obvious to me.
Saving config
A few reviews for these switches complain about them being forgetful, and I can see why. I tripped across this myself after setting an IP on my home network subnet, and then relocating the switch and finding it had returned to default 192.168.2.1 :(
All that’s needed is to press the ‘Save configuration’ button after making changes, but that’s a break from usual expectation that changes stick.
Conclusion
With VLANs set and config saved I’m happy with these switches, and I can see myself adding more as I add more 2.5G and 10G to my network.
Filed under: networking, review | Leave a Comment
Tags: 10G, 2.5G, 6 port, 802.1Q, 9 port, config, fiber, OpenWRT, SFP, SFP+, SL902-SWTGW124AS, SL902-SWTGW218AS, Sodola, tag, trunk, UI, UX, VLAN, VLANs
April 2026
Pupdate
It’s been mostly warm and dry, so plenty of opportunities for longer walks :)

Milo is now on the final cycle of his 4th chemo protocol, and it’s proceeding OK.
Toronto
We started the month in Toronto, which was a really fun trip deserving it’s own post.

Eyes
My cataracts are gone, and I now have a pair of Johnson & Johnson TECHNIS PureSee(TM) extended depth of field (EDoF) intraocular lenses (IOL). The procedure to fit them was as straightforward as I was told it would be; though I was glad that Charles Stross went a little ahead of me and provided the tip to take any sedation on offer.
It takes a while for things to heal and settle down, but I’m already pretty happy with my distance vision. Computer work and reading is another matter, and I’m still figuring out which glasses I’ll need. EDOF lenses are supposed to work down to intermediate distance, but I fear my home office monitors are just a little too close. That’s maybe not so bad, as I quite like having blue filter lenses when doing computer work. I just need something better than the cheap readers I got for reading restaurant menus whilst wearing contact lenses for skiing.
I may also be in the market for some new sunglasses (maybe even some varifocals for reading books outside), as I seem to be much more sensitive to bright light than I have been for the last 20y or so[1].
Complications
Everything seemed to be going fine until my one week check, where they picked up high intraocular pressure (glaucoma). They wouldn’t let me go home until it was normalised, which meant taking some pills, and a new eye drop regime for the next few weeks.
OpenWrt
I missed the release of OpenWrt 2025.12 at the end of last month, and it’s already at a .2 patch.
Upgrading has become really easy with ‘Attended SysUpgrade’ (ASU). I was able to go from 23.05.x on my router and WiFi access points in a matter of minutes. All the config and packages carried over without a hitch :)
Even better, the manual install of NoPorts I had on my router got automatically replaced by the csshnpd and luci-app-csshnpd packages that are now in upstream :)
Gemini Pro
I mentioned last month that I’m using Gemini CLI a fair bit, which was a good reason to take up the offer of a free year of Gemini Pro for Google Developer Experts (GDEs). But… I first had to move my GDE account from Atsign’s Workspace to my personal gmail. I’d say the migration has been worth it, as I get much better access to premium models.
Solar Diary
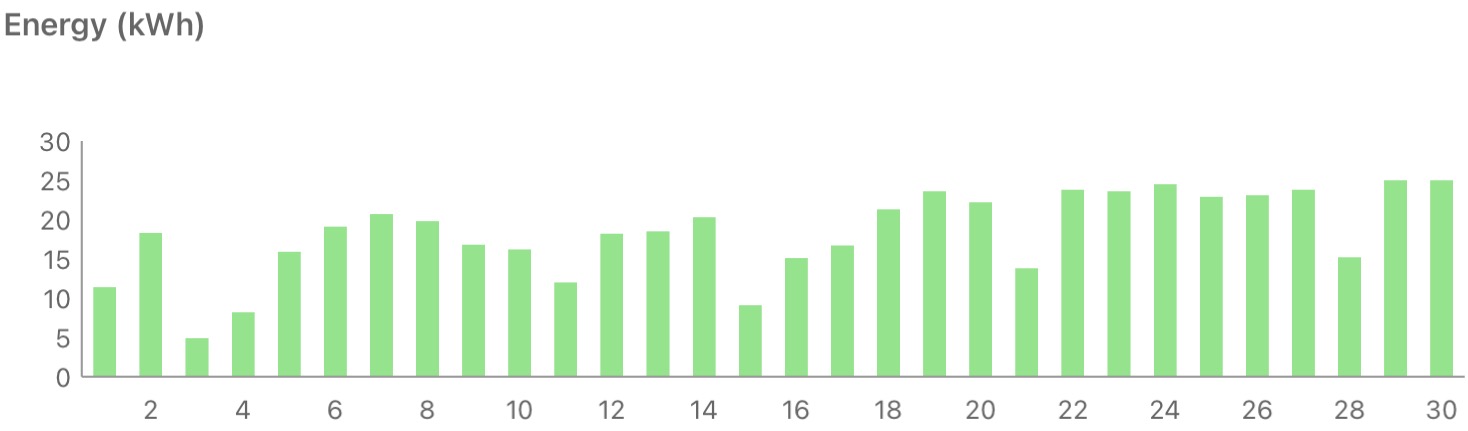
The sunniest April since the system was installed :)
Is iBoost worth it?
As part of the install I got an iBoost device, which diverts excess production into the hot water tank immersion heater (rather than it going for export). It’s quite a complex bit of kit, doing pulse width modulation (PWM) in order to work over a wide power range. I paid £428.57 for mine (though it seems the newer iBoost+ is available online for a little less).
I’ve been meaning to build a payback model, but instead I got Gemini to write me a Python script. The outcome isn’t great… the whole thing is predicated on expensive gas and miserly export tariffs. Running the numbers for the present gas price and my old ‘smart export guarantee’ (SEG) rate it takes about 70y for the iBoost to pay for itself. With the SEG rate I’m presently getting I’m better off exporting the electricity and using the money to buy gas for heating water :0 That’s not very eco, but that’s where we are in a topsy turvey UK energy market :/
Note
[1] Until my 30s I’d wear sunglasses pretty much all the time outside, but then I switched to baseball caps. Seems like I might now favour both.
Filed under: monthly_update | Leave a Comment
Tags: cataract, EDoF, eye, glasses, glaucoma, iBoost, IOL, Miniature Dachshund, NoPorts, OpenWRT, pupdate, solar, surgery, Toronto
Toronto
TL;DR
Toronto is a fantastic city, with plenty to keep us entertained over our 6 night stay.
Why Toronto?
We’d originally talked about returning to Halifax Nova Scotia, which we last visited in 2000; and then $wife announced that she’d like to go somewhere new.
Getting there
We picked flights with Air Canada on their A330, choosing the extra legroom seats in 34 H&K, which is a nice setup for couples travelling together. The flight was entirely unremarkable other than having a decent IPA on offer in the shape of Hop Valley Bubble Stash.
Hotel
We picked the Riu Plaza Toronto because it seemed to be the only hotel offering inclusive breakfast (and also well reviewed). It was a fantastic base for the trip with a spacious and comfy room. The reception area was lively, but not too busy, and we always got a friendly welcome on our way through to the lifts.
Breakfast was busy each day, but we only had to wait in line for a table for more than a moment once. The buffet selection offered plenty of variety, and got our days off to a good start.
Despite taking my gym clothes I didn’t use the gym apart from as a source of water for my hydroflask.
I’d definitely choose the hotel again, and for a brand I’d not seen before Riu is on my radar as an operator that’s getting things right.
Activities
Walking around
Our first day started with a huge trek around the city, taking in many of the spots that had been recommended to us by friends who’d visited ahead of us, and local colleagues. Our route took in the lakeside, St. Lawrence Market, The Distillery, and The Well.

Other days included Graffiti Alley, exploring Chinatown and the shoreline parks to the East of the Entertainment District.

Meeting the team
A bunch of Atsign folk are based in Toronto, and our head of sales was in town for some meetings; which provided the perfect excuse for a get together. It was wonderful to meet folk in person who are normally talking heads on a Zoom (and apparently I’m taller in real life!).

Art Gallery of Ontario
One of the local tips was to visit, the Art Gallery of Ontario (AGO) on ‘First Wednesday Night Free‘, which was perfect timing as it coincided with our first full evening in town. I’d booked tickets earlier in the week, which might have been a good thing, as it seemed popular.
Niagra Falls
Niagra Falls should be a 2h20 train ride from Toronto Union station, but it turned out that the lines were blocked due to a derailment, meaning we had to switch to a bus at Burlington, which is around half way there. The journey was thus less comfortable than it might have been, but we still got there in good time.
The walk from the railway/bus station is very straightforward, as it follows the path of a disused railway line.

After wandering along the promenade by the falls we had lunch in the Skylon Tower, which provided a fantastic view.
Islands
We had a lucky break with the weather for our day visiting the Toronto Islands, as it was sunny and warm(er) (after being near freezing on the days before and after). The ferry took us to Ward’s Island, and we walked to Gibraltar Point Lighthouse before turning back.

It’s easy to see why it’s a popular spot in the summer.

Comedy
‘Consumption-friendly’ was a new euphemism for me, but we didn’t pick the club describing itself that way. Instead we headed to the Backroom Comedy Club for a set featuring Tyler Horvath. It was a fun, intimate venue; and Tyler was great, along with the line up of local acts who warmed up for him.
Monet Expo
Claude Monet: The Immersive Experience is a similar setup to the Van Gough Immersive Experience we went to in Singapore a few years ago; though it was a lot less busy, and a bit more of a schlep to get there. Being less busy meant it felt much less pressured in terms of moving along to make space for the next wave of people, which made for a relaxing trip :)

Food and drink
I’d got a bunch of craft ale recommendations from a friend visiting Toronto a few weeks previously, some of which I followed up, some we didn’t find time for. It felt like everywhere had good beer and good food. Bar Hop got our poutine fix sorted on our arrival evening. After meeting the team at Blessing in Disguise we returned for some excellent charcuterie, and more great service from Daryl. There was a bit of a line to get into Amsterdam Brewhouse after our islands trip, but it was worth the wait for the brisket (and beer). I think they were caught out a little by the nice weather, as the line was even longer as we left.
Maybe the best meal of the week was at Koh Lipe, which had been recommended by a colleague. But we also both really enjoyed Byblos.
There were of course donuts from Tim Hortons, including some of their Easter specials; though the really special ones were the maple butter…
One thing I wasn’t expecting was so much (good) local wine, and if we’d had more time a winery tour might have been fun.
Getting around
Toronto has great public transport, with an integrated payments system called Presto that works across trains, subway, trams and buses. After being initially pointed at the Presto app, I figured out we could just use contactless (inc Apple Pay).
Maps bother
Unfortunately Google Maps, Citymapper etc. don’t seem very savvy about getting around using that integrated system. We had to figure out for ourselves that we could connect from subway to tram and save on the walking a little[1].
The maps apps were also terrible at dealing with closures and interruptions. There might even be a notification in the app, but the data hadn’t been factored into the picture being presented. It’s a good job we left early for the comedy club, as it turned out the 1 subway was suspended on exactly the segment we needed for the start of the journey :(
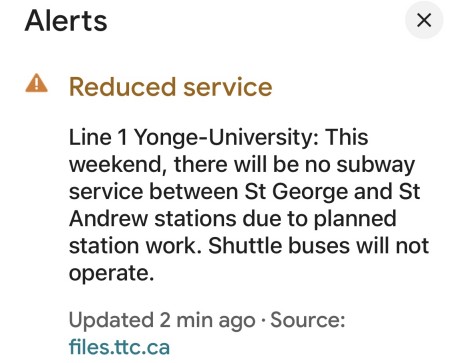
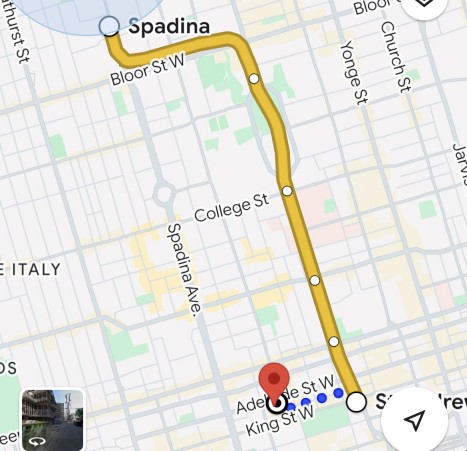
After spending time in cities where the apps correctly (re)route this was a bit jarring :/
Note
[1] This would have been handy to know on arrival, and saved us on getting a (ripoff?) taxi from Union Station to the hotel.
Filed under: travel | Leave a Comment
Tags: art, Atsign, beer, comedy, food, hotel, Islands, Monet, Niagra Falls, Riu Plaza, Toronto, travel
March 2026
Pupdate
We’ve (finally) had some warm and sunny days, so the coats have mostly been off for walks :)

Bath Half
$daughter0 is in her final year of her degree at Bath, and after getting into running last year she decided to run the Bath Half with some friends. That provided a good excuse for a weekend in Bath to support her (and of course visit some of our favourite restaurants and bars) :)

She completed the course in a (personal best) little under two hours.
AI training
Early in the month Google held an AI ‘train the trainers’ event at their London HQ. Attendees were a mixture of Google Developer Experts (GDEs), Google Developer Group (GDG) organisers and meetup organisers for various other Google platforms.
Whenever GDEs bump into each other for the first time it’s common for them to ask ‘what type are you?’ (meaning Android, Cloud, Dart/Flutter, Web or whatever), but at the community dinner somebody observed “we’ll all be AI by the end of the year”. That might not play out in practice, but I have a sense that it’s spot on in principle. Product specific knowledge isn’t the lever it used to be, versus being able to construct a good prompt.
The day itself gave me the chance to try out Gemini CLI and Antigravity. It was time well spent, as the following afternoon I got about a week’s worth of work done with Gemini CLI.
Conferences
The third week was very busy with two conferences back to back. It’s the first time I’ve ever spent a whole week in London, as the early starts and late finishes meant daily commuting wasn’t really practical.
Both QCon London 2026 then Monki Gras 2026 were (I think) the best yet :) More in the linked posts.
USB Shaver chargers
Whilst in Bath I went to use my shaver on the day of the race and nada… out of juice. Thankfully the front desk at the Doubletree was able to help me out with a shaving kit, but I was annoyed that I needed one.
The USB shaver charger I made a few years back is fine for longer trips (when I know I’ll need a recharge), but a little bulky to always have with me.

So… I went looking on Amazon and AliExpress, and found that other options are now available. I ordered a couple of these from AliExpress, though it seems similar ones are also available on Amazon (affiliate link) for a few pennies more, but faster shipping. They’re small enough that I can have one in each of my travel packs (UK/EU and US), and I already have the USB C adaptors there. On reflection I may only need one, which can live in the shaver case.
Cataracts
I’ve been back for more measurements and consultation, and my operation is booked in for next month.
Solar Diary
Not the best March so far, but one of the better ones.
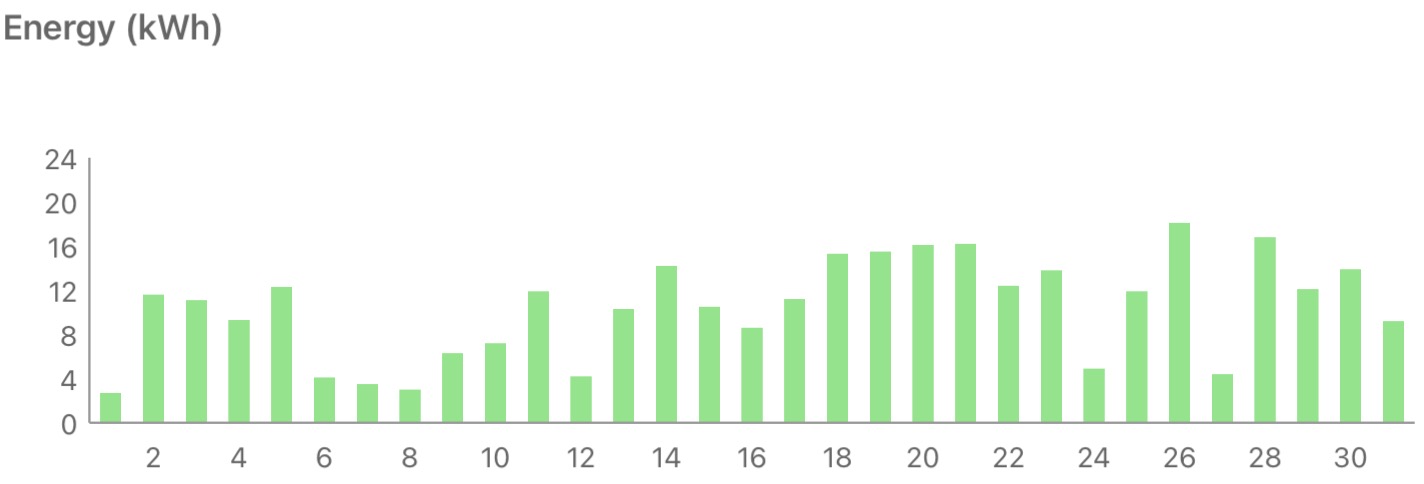
Filed under: monthly_update | Leave a Comment
Tags: AI, Bath, cataract, conference, conferences, dachshund, GDE, half marathon, Miniature Dachshund, Monki Gras, pupdate, QCon, solar, USB-C

