February 2026
Pupdate
It’s been a pretty dank February, so the coats have mostly stayed on for walks. But the boys have been enjoying their usual doggy mischief.

Milo is now half way through his 4th chemo protocol, and the second half has previous been easier as the pace slows down to vet visits every two weeks.
Cataracts
On the second day in Les Arcs I noticed that my vision wasn’t right, initially thinking I’d not put my right contact lens in correctly (the only time I wear lenses these days is for skiing).
After some fussing with lenses and staring at the hotel sign opposite my room I figured out that I could (sort of) fix things up with a stronger lens (an old prescription left lens), but there was definitely something wrong, and I booked the first appointment I could get for an eye test on my return.
Before I even got in front of an eye chart, the machines confirmed something was wrong. My right eye correction had jumped from -1.50 to -4.75 :0 It didn’t take long for the optician to see what was wrong, a cataract; and she referred me for specialist treatment. In many ways this was a comforting diagnosis, as of all the things that could be wrong it’s something that’s relatively straightforward to fix.
Three weeks later and I was at the optometrist for pre-op tests on the NHS path; but I’m now waiting for a private consultation at the end of next month, as I’d like a new lens that corrects my distance vision and astigmatism. After wearing glasses and contact lenses since I was 10 I might be free of them.
Meanwhile I’m wearing a contact lens and my varifocals.
Shingrix Pt.2
When I got my first Shingrix vaccine back in December the pharmacist warned me that it would kick my butt, and she was right. This time around I was told things would be easier, but they weren’t. If anything the aches etc. were even worse. Hopefully it’s all worth it to reduce my risk of dementia.
Protest
I’ve been going along pretty regularly to monthly meetings of my local Humanists group. A busy meeting might be a dozen people, so I wasn’t at all expecting what happened at our meeting on ‘Asylum and immigration: a compassionate, informed humanist approach‘.
Perhaps having our local MP Alison Bennett as a speaker should have tipped me off; but I was unaware of the building drama until some dinner guests the night before said “see you in the morning, we’ll be there at the counter protest”. I guess that’s what keeping off a diet of toxic social media does for you :)
I wish I’d taken a photo when I got there, but it was bucketing with rain, and I just wanted to get inside. There was a thin rabble of ‘stop the boats‘ protesters chanting their slogans on the outside of a police line with around 15 officers. Inside the line was the much larger counter protest group, including my friends. Beyond that the venue was pretty much at capacity, with hundreds of folk who’d come along. The speakers were all excellent, and it was good to meet some new folk as I spoke to those sat nearby.
It will be interesting to see if our ranks swell at the next meeting on the much less controversial topic of ‘Exploring our Humanist heritage’.
British Museum
I’ve been to the Natural History Museum and Science Museum more times than I can remember (starting back at my first trip to London when I was 7), but I’ve never been to the British Museum. We decided to do something about that during $wife’s half term break, which provided a good excuse for a day up in ‘Town’.
“Why do we have to be there at 2pm?”… ‘that’s when I booked the tickets for’. “I thought it was free?”… ‘it is, but you can reserve an arrival time (and they strongly encourage a ‘donation’).’ I was glad we had booked a spot, the line of people who’d just shown up without doing that was enormous, and not moving very fast. We went to the tent as directed, did our audience participation security theatre, and got inside in a matter of minutes.
I wish I could say it was great to see the Rosetta Stone, but the crowds made it impossible to see the business side of it. The crowds were less of an issue for the Elgin Marbles, as there’s just so much more of them. Though far too many came with signs to the effect of ‘missing head is in Athens’. Perhaps more impressive were some of the Assyrian exhibits; but I think we both came away feeling that none of that stuff belongs in London, and we should give it all back.
As we explored the further reaches it became less busy, but also more mundane. Things like those we’ve seen in many other museums in many different places. I was glad to have checked it off the list, but I don’t think I’ll be hurrying back.
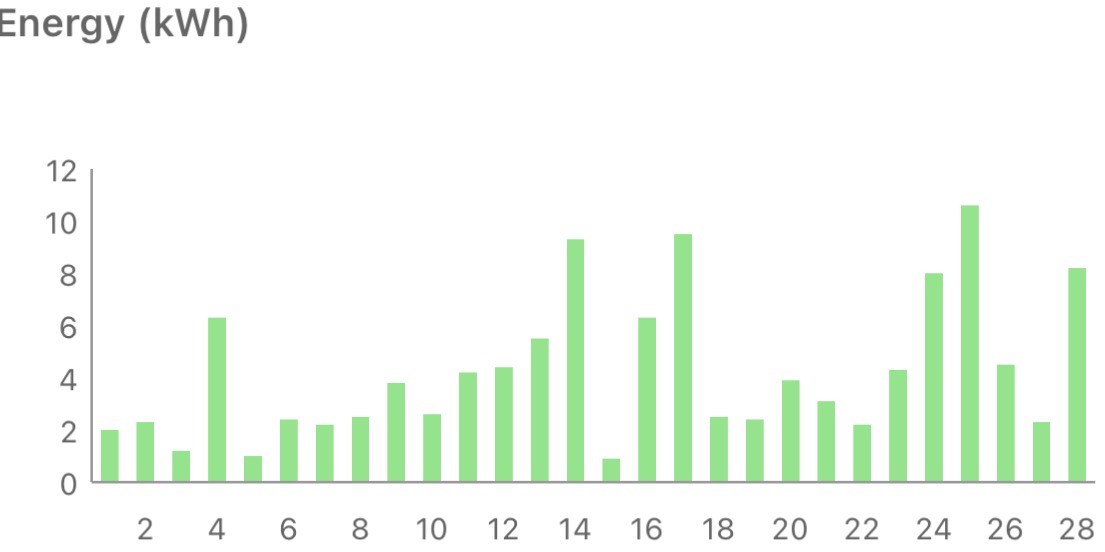
Solar diary
A dank month for dog walks also meant a dark month for solar production – the worst February yet :(
Clay Hunt VR
In previous posts I’ve been dubious about whether practice in Clay Hunt VR carries over to an improvement in real world clays shooting. Now I’m more persuaded, having put in some of the best rounds of my life (despite the cataract). I’m finding that I have better focus on the target, and more instinctive aim.
After the Shingrix vaccination I woke one morning to a very painful right arm (possibly ‘frozen shoulder‘ though also maybe just lying awkwardly). This made shouldering the VR gun an exercise that I didn’t want to repeat. Fine for a quick round of skeet, but too tiring for anything else. So I did a game of ‘Duck Hunt’ purely shooting from the hip. As the saying goes… “Not great, not terrible”. I could probably do better with more practice, but thankfully the arm was back to normal after a couple of days :) The point however is that with unlimited free ammo you can practice stuff that would be reckless in real life.
Filed under: monthly_update | Leave a Comment
Tags: British Museum, cataract, clays, dachshund, humanist, Miniature Dachshund, Shingrix, shooting, solar, vaccine, vr
TL;DR
GitHub Pages is a practical way to host a low volume repo for apt and yum/dnf. The relevant metadata can be generated using GitHub Actions, and the process can be triggered by a release from the source repo.
Background
In my last post I wrote about creating .deb and .rpm packages (for our Dart binaries), but most people would rather not install those things manually with low level tools. They’d prefer to use their package manager, and then it can take care of subsequent updates.
Those package managers rely on metadata that’s added around the packages themselves. So that needs to be generated.
More fundamentally this stuff needs to be hosted somewhere. It’s ‘just’ a website, but websites need servers, and those servers need connectivity. GitHub Pages provides a free way to do the hosting, so long as you’re comfortable with its limits – no more than 1GB of files and 100GB of bandwidth/month.
Creating metadata
Once there’s a new release in place I need to download the .deb and .rpm packages and create the metadata for their respective repos.
The download piece is common across both types, using the gh command line tool to fetch files from the latest release.
Apt
My update-repo workflow for apt then uses the apt-ftparchive tool to generate metadata and gpg to provide signatures.
Rpm
Yum/dnf repos are ostensibly simpler, but that doesn’t show very much in the different update-repo workflow[1]. The main difference is that it uses createrepo_c for metadata.
Triggering the rebuilds
Our normal process for a NoPorts release is to first do a pre-release, which creates all the binaries and packages. Once we’re happy with that the release can be promoted to ‘latest’ and at this point we want to trigger updates to the apt and rpm repos.
That’s taken care of by an update-packages workflow that listens for the release being promoted, then fires off a bunch of repository_dispatch messages that start the update-repo workflows.
Brewey bonus
We also rebuild our homebrew-tap at the same time. Homebrew is much easier to deal with from a hosting perspective as it doesn’t involve slinging around huge packages full of binaries. It’s a very GitHub friendly approach that puts metadata in place pointing to the archives from the GitHub release – so no worries about storage or bandwidth limits.
Busting past the limits
A typical .deb/.rpm for NoPorts is around 50MB, and we support 4 architectures, making each release around 200MB. So we can fit around 5 releases in place before we need a housekeeping job to start clearing out old versions. Not great, not terrible.
That also means that we get around 2000 downloads per month before a repo hits its bandwidth limit. I’d consider that a quality problem (more people using NoPorts). But it’s good to have a plan…
Package URL
The GitHub pages sites are configured to use apt.noports.com and rpm.noports.com using a custom CNAME. So if we need to move hosting elsewhere we can just point the DNS to the new server/service.
Cheap hosting
Free is everybody’s favourite price, which is why I like GitHub Pages (for this and many other things). But I also appreciate that free gets exploited and abused, which is why GitHub have to have limits.
For a previous project that involved lots of people downloading large binaries I used cheap Virtual Private Servers (VPS) of the kind that show up on LowEndBox. It’s possible to get servers with more space than we’ll ever use, and TB of monthly bandwidth, for a few $/m. But… VPS providers can be flaky, and there’s an admin overhead in running those servers.
My likely upgrade route today would be AWS CloudFront. Corey Quinn recently posted The Complete Guide to CloudFront’s Flat-Rate Pricing, and $15/m for 50TB of data transfer is a bargain; and that’s about 1M package downloads.
Conclusion
It’s pretty straightforward to automate package metadata using GitHub Actions around the various package management tools, and GitHub Pages provides free and easy hosting for a low volume site.
Pages won’t be enough for higher volume, but at least the investment in generating metadata etc. isn’t wasted, as that can be carried over to a hosting environment that offers more storage and bandwidth.
Note
[1] After taking an afternoon to put together the apt automation the rpm derivative took a few minutes, and worked first time :)
Filed under: howto, software | Leave a Comment
Tags: APT, aws, bandwidth, brew, CloudFront, deb, dnf, GitHub Actions, GitHub Pages, homebrew, hosting, rpm, VPS, yum
TL;DR
nFPM makes it very easy to put your binaries into a Debian .deb or RedHat Package Manager .rpm file.
Background
We’ve been using full stack Dart and Flutter at Atsign since the dawn of the company in 2019, so when NoPorts came along we released the binaries in tarballs (or zip files) from GitHub releases.
But… there are lots of good reasons for better integration with standard package managers like apt and yum/dnf, not least of which is that their update mechanics ease compliance with the forthcoming EU Cyber Resilience Act (CRA).
Packaging as .deb or .rpm is the first step along the road, and Gemini helpfully pointed me towards nFPM.
Config
nFPM is configured by a YAML file, and comes with a fairly bare bones example. I found it helpful to look at more complete working examples for existing projects like Kong, and Gemini was helpful in pointing them out.
My final nfpm.yaml isn’t especially complex, but it is long(ish) as we ship a lot of binaries.
Cross compiling
We ship binaries for all of the platforms and architectures supported by Dart. Most of these can be built natively using various flavours of GitHub Actions runners, but not linux/arm7 or linux/riscv64. So those builds were done inside of Docker containers.
But… Dart can now do cross compilation, so it’s much easier (and quicker) to produce the binaries that way :)
Linting
The nFPM ‘Tips and Hints‘ says: “It is recommended to run lintian against your deb packages to see if there are any problems.”, and for me that flagged up a bunch of stuff that needed tweaking.
Man pages
One of the issues was that we didn’t have any man pages for the binaries. Fortunately they can be created (on the fly so they don’t get out of date) using help2man, which takes the output of –help and turns it into a man page.
This did however create some ‘fun’ for the cross compiled binaries, as help2man then needs to run them on a foreign architecture. Fortunately QEMU can take care of that (along with some LD_LIBRARY flags so that the right dynamically linked system libraries are picked up).
GoReleaser
nFPM is a sub project of GoReleaser, which as its name suggests is a tool originally developed to help the release process for stuff written in Go (aka Golang).
GoReleaser has subsequently expanded its language support to include Python, Rust, TypeScript, and Zig. Sadly there’s no support for Dart yet, though there is some discussion about it. One of the stumbling blocks was a lack of cross-compilation support, so that’s at least partially solved[1].
Conclusion
Adding .deb and .rpm packages to our GitHub Actions based continuous delivery (CD) pipelines using nFPM has been pretty straightforward. It’s also prompted some rework to make use of cross compilation in Dart rather than separate jobs running in Docker containers, and that seems to be making builds quicker and more reliable.
Take a look at the ‘multibuild‘ action workflow for all the fiddly details.
Note
[1] Dart can’t yet cross-compile between (all) platforms. So I can get Linux binaries (for any supported architecture) from Windows or macOS (and of course Linux itself), but I can’t get macOS or Windows binaries from anything but their own system.
Filed under: Dart, howto, Uncategorized | Leave a Comment
Tags: APT, cross compiling, Dart, deb, GitHub Actions, GoReleaser, help2man, lint, lintian, man, nFPM, QEMU, rpm, yum
January 2026
Pupdate
The New Year had barely begun and we had a cold snap and some snow.

Milo’s back in remission thankfully, though there have been a few hiccups with his treatment this time around. Some of that’s expected (low neutrophils), but the vets struggling to get canulas in due to vein scarring is new and unwelcome :(
Mixer repair
We’ve had a Kitchenaid mixer for many years, and it gets fairly regular use for making dough and cakes, and sometimes mincing meat.
The dough mix on New Year’s Eve sadly broke it, and subsequent use for making a Tiramisu led to noises that didn’t chime with any sense of mechanical sympathy.
I followed ‘Mr Mixer’s’ How to Completely Rebuild Your Tilt Head Mixer and found a cog with teeth stripped off (and a bent pin):

It took a few days to get spares (because of New Year). I was able to get the (genuine) cog and new grease from Amazon (affiliate links), but had to use another place (and expedited shipping) for the M4x17 dowel pin.
Putting it back together was pretty straightforward (with guidance from ‘Mr Mixer’), though all that grease makes for a messy job:

I wish I’d taken a before picture for comparison. The severed cog teeth were embedded in the revolting old grease. But it was so awful that I was told not to.
Having (unnecessarily) taken the motor control apart I needed to recalibrate that; but it’s been running smoothly since :)
Skiing
A week in Les Arcs was a lot of fun. Enough to deserve its own post.

Burns supper
This was my third time at a Scotch Malt Whisky Society (SMWS) Burns Night, but things were a little different this time around. Firstly a new venue, at The Crypt of St Etheldreda’s, which is near the London tasting room. This provided a LOT more space than the basement of The Bleeding Heart, and I’m guessing they had twice as many folk attending. There was also live music and singing, which added to the fun, but did make conversation a little difficult as we had the table nearest to the stage.

I was very lucky to win a bottle in the raffle, a lovely 19yo Highland Park:

I’m looking forward to trying it, hopefully with some of the friends who joined me that evening; and especially after reading the review from Two Whisky Bros.
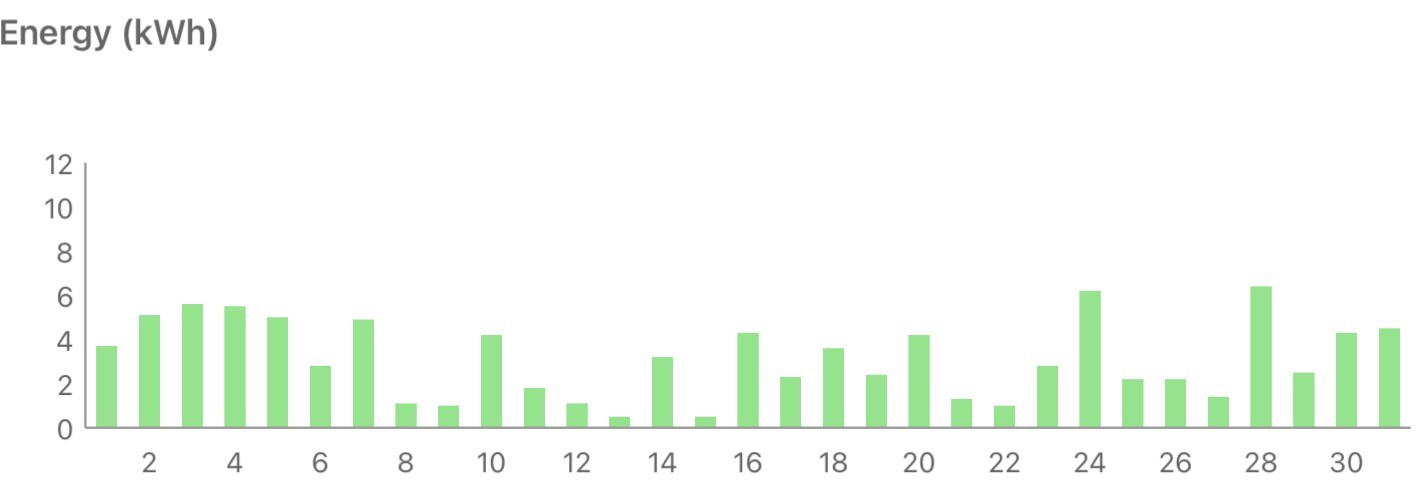
Solar Diary
I described last January as ‘dim and grim’ and this one wasn’t much different :/
Filed under: monthly_update | Leave a Comment
Tags: Burns Night, dachshund, Kitchenaid, Miniature Dachshund, Mixer, pupdate, repair, skiing, solar, whisky
After previous trips to The Three Valleys and Espace Killy, Paradiski felt like a way to complete the set of long established multi location French ski areas.
Inghams again
Having organised the last few trips with Inghams, they were where I looked first, and in the end the provider I chose.
Getting there
Another flight to Chambery, though an earlier start than previous occasions. At least it’s only an hour from my alarm going off to Gatwick South.
Our departure was a little delayed due to fog at Chambery, but we made up time on the way, so arrival wasn’t too badly behind schedule. Of course we were then thrown into the usual chaos of Chambery arrivals, but I know what to expect now, and we weren’t in a hurry. We were soon on a (pretty full) coach to Les Arcs, and the transfer was about 2h15m as there were no traffic problems.
Self catering
I looked at a LOT of hotel options in Les Arcs and La Plagne, and nothing stood out. Maybe Le Savoire in Val d’Isere spoiled us. I’m pretty sure we’ll never find something so good again in terms of space and food.

Residence La Source stood out as well reviewed, and offered us separate rooms at a reasonable price.

I was a little worried about the 5pm check-in given that we arrived early afternoon, but thankfully the room was ready.

The apartments offer daily bread/bakery delivery, so that was breakfasts taken care of :)
Our ground floor room was right beside the ski room, which was ski in/out, so very convenient.
I didn’t plan on returning to the apartment during the day for lunch, but sometimes we were close by, and peckish, so it was super convenient.
Equipment
Our early arrival meant we could get skis and boots sorted in the afternoon, so no Sunday morning rush :)
Inghams provided vouchers for Intersport, which was a short walk from the apartment. They were friendly and efficient, though first glance at my skis bothered me that they were a little tired.

That first set of skis was OK, but the bases were a bit cut up (hardly surprising after 5-6 seasons); and I’m not convinced they were ever that good. After 2 days I made the call that they were OK, but not great, and returned to the shop for something else.

The chap in the shop told me that I was swapping a Lamborghini for an Audi, but if that’s the case it was a battered and temperamental Countach for a newer RS6. I was much happier on the replacement skis.
$daughter0 was given some Salomon skis that were described as ‘new’ but obviously not out for the first time. I think they meant new this season. She seemed to get on with them pretty well :)

Boots were Salomon, and utterly unremarkable.
The Skiing
With 425km of piste Paradiski is larger than Espace Killy, but smaller than The Three Valleys. It’s also considered to be less good for advanced skiers, meaning fewer black runs.
Getting over to the La Plagne side was easier than expected, taking about an hour. So it was practical to explore the whole area.
Sadly the weather and skiing conditions weren’t ideal. We had (some) snow most days, which meant that pistes weren’t being groomed; and for the latter half of our stay visibility was poor, with a lot of low cloud / freezing fog.
Best of the Blacks
‘Aiguille Rouge’ is an utterly fantastic run. It starts with an imposing steep section, and was a little lumpy in the following section, but after that it was a dream run of wide open piste that could be taken at speed. Worth the wait for the cable car, and it’s a shame conditions didn’t allow for more runs.
We stumbled on ‘Murs’ whilst trying the lower section of ‘Mont Blanc’ (as an alternative to Myrtilles mentioned below), and despite poor conditions it was enough fun to deserve a repeat.
Pick of the Reds
There’s a selection of Reds that run down into Les Arcs 1800, and there’s little to choose between them. They all offer decent sight lines, and the opportunity to wind on a little speed; though they all suffer from crossing blues, and the ‘slow down’ warnings that go along with that.
‘Secret’ was fun despite poor visibility and weather, so I’m expecting it’s an awesome run when conditions are good.
Beautiful Blues
‘Myrtilles’ looked lovely from the Pierres Blanches lift, and was a picturesque and entertaining run down to take the lift again.
The upper section of ‘Mont Blanc’ was nice and wide, making it easy to navigate any traffic.
The run home on ‘Edelweiss’ was often busy, but still fairly relaxing.
Food
We ate out most nights.
Papa Pizza became a regular haunt, with good choice on the menu, generous portions, friendly service, and a good beer selection.

I’d taken a long look at the Taj-I Mah as a hotel option, so we treated ourselves to a dinner there, choosing the five course daily menu. It was interesting food, well presented, and an amazing cheese selection.

Our first visit to 2134 (for fondue) was so good we chose to return for our last night; and that meal was tremendous. Highly recommended (especially for those who like an extensive wine list).

Ski Tracks
I’ve been using Ski Tracks for a while now, but it let me down a few times on this trip. The whole of my first morning disappeared, with the watch app just vanishing. I also lost an afternoon (and my fastest run of the trip), even though I definitely stopped recording :( Data was reliably getting into Apple Fitness, but sometimes not into the app, which is a shame, and annoying.
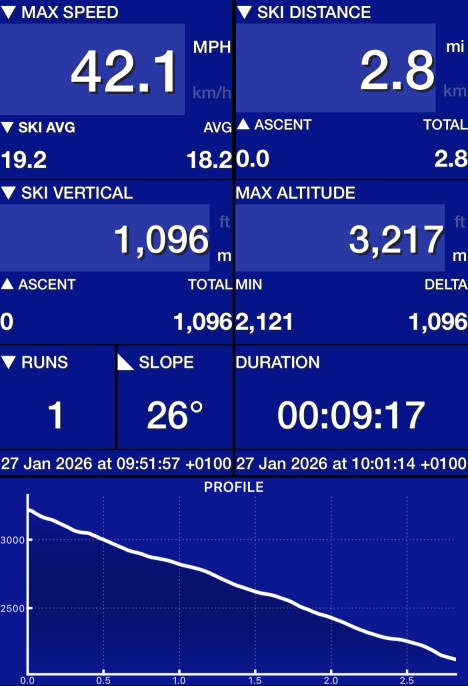
To compensate I found myself more frequently stopping and restarting recording, which helped a little.
Getting Home
Returning via Chamberry was (once more) a frustrating experience. A 5am start for a 5.40 bus only to then spend an extra 3h waiting around for the fog to clear and our flight to arrive. Perhaps the operators should adjust schedules around what actually works rather than mythical departure times?
Conclusion
Les Arcs was a lovely place to stay (and eat), and it was fun to explore over to La Plagne. We were a little unlucky with weather, and piste conditions, so the skiing wasn’t on top form; and even if it had been I’m not sure this is the best area for the type of skiing we enjoy (compared to The Three Valleys and Espace Kitty).
Filed under: travel | Leave a Comment
Tags: 2134, Aiguille Rouge, Chambery, food, Inghams, La Plagne, La Source Des Arcs, Les Arcs, Papa Pizza, Paradiski, Ski Tracks, skiing, skis, Taj-I Mar
TL;DR
Coding is no longer the constraint. It’s now cheaper than ever to make software. But there are supply side constraints on innovation, and getting apps to market. Who dreams up something worth making? How do apps get in front of users? There’s also a demand side constraint on adoption – how do people learn about the new possibilities available to them?
Background
I forwarded this post about multi-agent orchestration (and token exhaustion) to a colleague, and it got me thinking about where the bottlenecks are if agents can code whilst you sleep.
The irony here might be that it was Gene Kim who put Michael Tomcal’s post into my timeline, and he knows a thing or two about Theory of Constraints after re-spinning ‘The Goal‘ as ‘The Phoenix Project‘ and again as ‘The Unicorn Project‘.
Theory of Constraints
Let’s back up a moment… why am I even talking about constraints?
I’m very much a disciple of Theory of Constraints, through the work of Gene Kim and others in the DevOps community. It was the central organising principle for my work at DXC Technology, and continues to be a lens that I often peek at the world through.
Most systems will have a small number of constraints, and it’s a good idea to figure out which is the primary constraint; because if you optimise anywhere except for that constraint you’ll either be piling up work faster at the choke point, or building a wider highway down the road from where all the traffic is stuck.
Constraints and Software
Building software is expensive. I know that because I work in an industry where people get paid a lot (relative to say nurses and teachers, or even doctors and professors). Just take a look at levels.fyi for data.
We often conflate software engineering with coding, but is coding actually the constraint? Over my time in the industry there’s been a succession of (often overlapping) changes that have brought down the cost of coding:
- Higher level languages
- Integrated Development Environments
- Context aware autocomplete
- Visual programming
- Component libraries
- Open Source Libraries
- Outsourcing / offshoring / nearshoring
- No Code / Low Code
- AI coding assistants
- Agentic development
Getting from idea to code is cheaper than it’s ever been. But then the cost of getting from idea to code has kept falling (something like) 10x per decade, so arguably no seismic shift is happening.
Where do the ideas come from?
OK, so it’s cheaper than ever to get from idea to code. But who’s even having the ideas, and are they good ideas?
Richard Seroter recently wrote about an agentic adventure with ‘Will Google Antigravity let me implement a terrible app idea?‘. Refuting Betteridge’s Law, the answer here is yes. The AI tools let him implement a terrible app idea. They also let him implement the app terribly, but that’s probably material for another post, another time (meanwhile there’s discussion over on LinkedIn).
Why didn’t Richard implement a great app to show off Antigravity? My guess is that he didn’t have an idea for a great app formed an ready to go; whilst it was easy to dream up a terrible app.
The limit case – personalised apps for everything
I sometimes like to wonder what the limit case is for something – if we take it to the ultimate extreme. In this case, “what if everybody could imagine up perfectly customised apps for their every need?”.
It’s clearly ludicrous, because most people don’t even customise the settings on the apps they have. They don’t have the time, or the inclination to even learn what’s possible; which is why sensible defaults are so important, because that’s what most people will use.
People just want to get on with their lives and work, with minimal friction imposed by the tools they choose to help them with that.
The innovators and change makers spot problems they feel obliged to solve – itches they have to scratch. Everybody else is glad that somebody else is doing that work.
Supply side constraint #1 – innovation
This brings us to a limiting factor – a constraint. The set of people who have ideas for apps worth building is not everybody. It might be a larger set than the people currently making apps, but it’s finite, and probably not much larger.
It’s also worth noting that innovation is generally a team sport[1], which is why it’s great to see my pal Killian (along with his former colleagues from Meta) building tools expressly for teams.
Supply chain friction
Coding is only a small part of engineering, and engineering is only a small part of getting a product to market.
It’s one thing to get my app working at http://localhost:8000, or in the phone emulator on my IDE. Quite another to get it running on secure and robust infrastructure, or through the review process and published on an app store. That might not matter for the limit case above where I’m the only user. But it matters a lot if you want other people to use it; and a whole lot more if you want other people to pay for it. Chris Gregori sum’s this up with ‘Code Is Cheap Now. Software Isn’t‘.
Supply side constraint #2 – syndication
Entry level cloud hosting might be free, but there’s still work involved in using it; and if people show up then the bills will follow.
It’s a similar story for mobile apps. Apple and Google might not charge to get things into their stores. But the review process can often be slow and frustrating; and that can repeat every time there’s an update.
How do people know?
Ok. You’ve had a great idea, you’ve built the app in no time, it’s in a marketplace where people can find it (and maybe even pay). How does anybody with the need for what the app does even know?
This is a demand side constraint. People have limited time and attention; and they’re mostly already at saturation point with everybody else who’s shouting ‘buy my stuff’.
It’s really hard to get noticed. Dare Obasanjo recently posted some X screencaps of a Hendrik Haandrik thread that observed that:
In the last 3 months, about 24k new subscription apps were shipped…
Out of those 24,000 apps, a grand total of 700 (less than 3%) made more than $100.
Read that again
$100, not $100k
The odds are very much stacked against you
Demand side constraint – attention
How’s your better belly button fluff remover app going to get noticed in the sea of other apps? How do people worried about their belly button fluff even know that there’s now salvation? A lot of brands are spending a lot of money to get people’s attention (that’s what’s gotten us ‘filter failure at the outrage factory‘). You want your thing to be a viral hit, but all the social media sites are suppressing organic content in favour of more paid ads. It’s tough.
Conclusion
People have been asking ‘if AI coding is so great, where are all the apps?’. Hopefully I’ve shed some light on answering that question. The apps are stuck at various constraints that exist on both the supply side (having good ideas, and the dealing with supply chain beyond coding) and the demand side (getting people’s attention to know there’s something new that’s worth their time).
Theory of constraints tells us we should move our attention now to unblocking those constraints. It’s going to be a LOT of work…
And…
It would also be remiss of me not to mention Peter Evans-Greenwood’s excellent work on this topic, particularly ‘Are We in 1886? And 1919? ‘ subtitled “When a technology wave requires two grammars that history kept separate”:
The UK 1873-1896: Supply-Side Grammar. The technology worked but deployment was bespoke and expensive. The missing piece was coordination infrastructure for installation.
The US 1919-1925: Demand-Side Grammar. The technology was deployable but unaffordable for the mass market. The missing piece was coordination infrastructure for purchasing.
History kept these gaps separate. They never overlapped. Electrification solved its supply-side problem (1873-1896) decades before automobiles faced their demand-side problem (1919-1925).
Today, for the first time, both gaps must be solved simultaneously.
Update 19 Jan 2026
I had meant to say something about this post from Aporia (but forgot to weave it in):
What Claude Code has revealed is that most people either have mediocre ideas or no ideas at all. The tool is a force multiplier for those who already know what they want to build and how to think through it systematically; it elevates competence, rewards clarity, and accelerates execution for people who would have gotten there anyway, just slower. If you have a sharp vision and can break it into coherent steps, Claude Code becomes an extension of your own capability.
But there’s another mode of use entirely. For people without that clarity, the appeal is precisely that the input can stay vague; you gesture at something, hit enter, and wait to see what comes out. This is structurally identical to a slot machine: low effort, variable reward, and that intermittent reinforcement loop that hooks the susceptible. So the same tool that elevates the focused and capable is also manufacturing a kind of gambling behavior in people prone to it.
Update 9 Jun 2026
Alasdair Allan has posted A distribution of one, where he argues that people are now empowered to build their own personal tools. I’m with him some of the way… but it doesn’t explain why they bother to publish stuff to app stores, where it sits at the extremities of the long tail with approximately no users. If this stuff is intentionally just for yourself (or even friends, family or colleagues) there are much easier/cheaper ways of doing app distribution than publishing. I suspect one reason is that these author’s/publishers hope that they’re buying themselves a lottery ticket – the odds are hugely against them, but other people have viral apps that bring in the $£€.
Yesterday Dare Obasanjo shared some further insights on What happens when execution is free?
Distribution and fighting for attention becomes the challenge.
We can create infinitely more apps but there isn’t infinitely more human attention. The big winners here will be aggregators of attention and ad networks (e.g. Meta, Alphabet) who are now even more valuable.
Note
[1] My friend Jamie Dobson has a great post that includes a rebuttal of ‘The Lone Genius Myth’.
Filed under: code, technology | Leave a Comment
Tags: AI, attention, cloud, coding, demand, DevOps, economics, ideas, innovation, saas, supply, theory of constraints
CHOP #4 has worked, and Milo’s scan today shows that he’s in remission again (before even getting his Epirubicin).

This cycle of chemo seemed to go better than previous protocols, until we got to the planned Epirubicin last week, and his neutrophils were too low. So we were back at North Downs Specialist Referals (NDSR) today for another go, and things were in better shape.
Chlorambucil prescription
For previous protocols NDSR have provided the Cholorambucil (and previously Cyclophosphamide) that’s been administered by my local vet. 6mg (3x 2mg tablets) was coming in at £41.77.
This time around the oncologist suggested that he give me a prescription (£20) and that I get the tablets from an online pharmacy such as Weldricks, where the tablets are £2.49ea. I registered an account, uploaded a scan of the prescription, and placed an order as soon as I got home from NDSR. With refrigerated shipping all 12 tablets (for the whole protocol) came in at £36.67, saving £110.41 over the protocol.
But then nothing happened for a few days, and the clock was ticking towards the day the first dose was due. On closer reading of the confirmation email I found:
If you have a Vet controlled drug order you must send your paper prescription to the address below.
There had been no mention of this in the ordering process :0
I got the paper prescription into the post. But later that day (before it could possibly have arrived) there was a shipping confirmation, and I was able to pick the next day to receive the tablets.
It was a little stressful, but we’re all set now :)
Prompt payment from ManyPets
As I write this ManyPets are up to date on paying all claims, with the last two settled same day :)
The claim for the prescription mentioned above took a little longer to settle, as I hadn’t claimed for the online pharmacy invoice whilst waiting for it to be fulfilled. But that’s all straightened out now.
Past parts:
Filed under: MiloCancerDiary | Leave a Comment
Tags: chemo, chemotherapy, Cholorambucil, Epirubicin, insurance, lymphoma, ManyPets, Miniature Dachshund, online pharmacy
December 2025
Pupdate
It’s been quite dry over the Christmas break, which has encouraged some longer than usual walks that the boys have enjoyed.

After a scan at the start of the month Milo has now almost completed the first cycle of his 4th modified ‘CHOP’ chemotherapy protocol. As before, low neutrophils mean we’re a little behind the ideal schedule; but also he’s never made it through the early cycles without some delay.
Gigs
Steve Hogarth
This was our third time in as many years seeing ‘h natural’ at Trading Boundaries, and he really seems to have settled into enjoying the venue. He treated us to another selection of covers, solo material and Marillion tracks; and there was even more audience participation than before, including a performance of Talking Heads ‘Once in a Lifetime’ that had about half a dozen people joining Steve at his keyboard.

Wakeman and Wilson
On a trip with the kids to look at the Roger Dean gallery $wife was persuaded to get some tickets for the Christmas event featuring Adam Wakeman and Damian Wilson. It was a lot of fun, and seems likely to become a regular feature for future festive seasons.

Hackers in the House
I was aware of the first Hackers in the House, last year, but only after the fact. So when it popped up in my Mastodon feed this year I applied to participate.
It was weird to do an event where I didn’t know anybody else; though I did get to meet a couple of folk I knew from the Internet :)
Was it worth a day to learn how the policy sausage is made (and hopefully make future policy better for practitioners)? I think yes – the folk from government seemed very receptive to the input from the room.
My one big takeaway (my own analysis). During Brexit we talked about Britain as a ‘rule taker’ or ‘rule maker’. My read on what’s now happening is that we’re a ‘rule fudger’. The EU is pushing ahead with some pretty big legislation in the cyber security space, such as the Cyber Resilience Act (CRA). Meanwhile the UK government is publishing voluntary codes of practice. For a lot of the areas we talked about it felt like it doesn’t really matter what UK policy is, because the CRA will be shaping what most suppliers actually do.
Health & Fitness
A year of monthly challenges
I’ve had a couple of years where I’ve completed 11 monthly challenges, with one where I frustratingly missed December; but this is my first time getting the complete set.

NHS Healthcheck
“You might think you’re healthy, but you really have no idea, as you’ve not seen a doctor since before Covid”, was becoming a frequent refrain from $wife. I was also a little concerned that I seem to be getting more colds than usual in the past few years. Some sort of deficiency? It was time to find out.
My doctor’s surgery online booking system offered an NHS Health Check, which seemed to be what I needed (and without bothering an actual doctor for an appointment). I had to book two appointments – one for blood to be taken for tests, and another a couple of weeks later to go over the results.
I knew ahead of the second appointment that my blood tests were all normal, as the results appeared in the NHS app on my phone. The consultation was spent going through a lifestyle questionnaire, and that didn’t reveal any surprises or demand any changes. Hurray :) Except I still don’t know why I’m getting so many colds? Aging, more stuff going around post Covid, population wide immune problems post Covid – they’re all in the mix, with no clear answers.
Shingrix
The evidence is mounting that the Shingles vaccine provides protection against dementia, and I don’t want to wait another decade to qualify for it on the NHS. So that was quite an expensive trip to my local pharmacy :0
The pharmacist warned me that it would likely kick my ass, and she wasn’t wrong. I went to bed with a sore arm, and aches all over, and woke a few hours later to shivers. But, by the morning I was feeling OK. Apparently the second dose (due in 2 months) isn’t usually so bad.
Washing machine repair
Our 13 year old Bosch washing machine started leaving puddles on the floor. As the door seal was disgusting, I ordered a replacement, which took a couple of days to arrive. I did that despite not finding any obvious damage that would allow water out.

The new seal took about an hour to fit, following this excellent guide. Running a test wash afterwards seemed fine, but then there was another puddle :(
Somehow I’d failed to spot that the hose for the fabric conditioner had come off. So the machine was getting to quite late in a wash cycle then squirting water.

Getting to the hose to reattach it meant repeating some steps from the seal replacement, but by then I knew what I was doing with my new hook pick and the other tools involved.
Although the replacement seal wasn’t strictly necessary, it’s nice that the machine is looking like new again :)
New IT bits
I didn’t really want a new printer and graphics card, but events forced my hand.
Printer
The Dell 1320CN that I got 15y ago started printing with coloured stripes that weren’t going away. Perhaps a victim of too little use now that $wife does most of her printing at work.
I considered not replacing it, but when a deal came up on a Brother HL-L3240CDW I went for it. It’s small, quiet, network connected, and does duplex colour printing; so everything I need. Consumables look reasonable, but only time will tell on that front…
Graphics card
I did a separate post on my Silent PC GPU upgrade, but it was a bunch of money and time just to avoid forced obsolescence because Nvidia doesn’t play nicely with Linux :(
Maybe one day I’ll do some gaming where I can marvel at how much smoother the pixels are :/
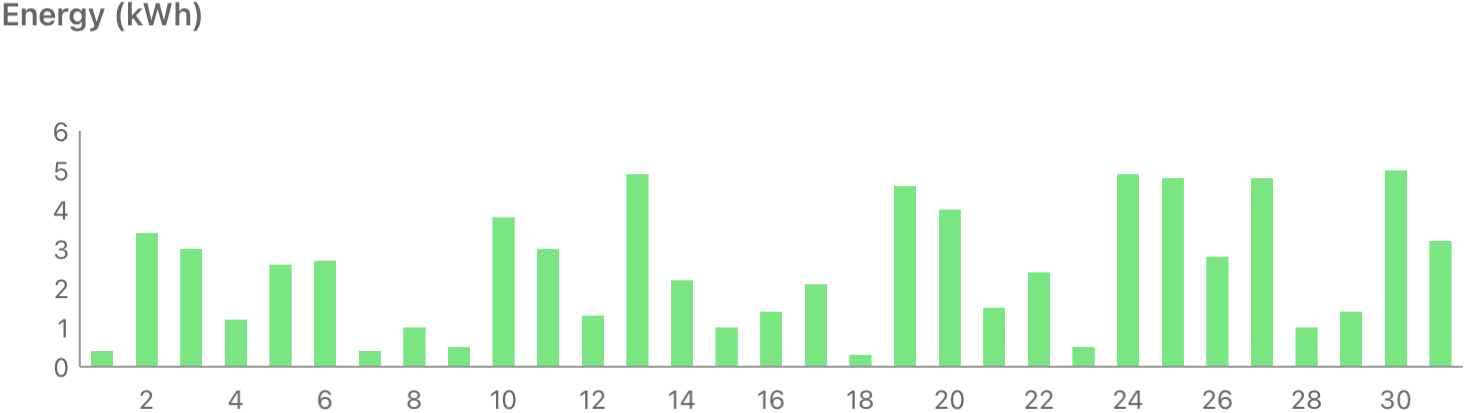
Solar diary
December is cold and dark, but this December was less dark than the past couple of years, with some bright sunny days.
VR
Last month I felt that practice in Clay Hunt VR was throwing off my real world clays game. This month, not so much.
Filed under: monthly_update | Leave a Comment
Tags: Adam Wakeman, chemotherapy, clays, Damian Wilson, door seal, fitness, gig, GPU, graphics card, Hackers in the House, healthcheck, Miniature Dachshund, printer, pupdate, repair, shingles, Shingrix, solar, Steve Hogarth, Trading Boundaries, vaccine, vr, washing machine
Silent PC GPU upgrade
TL;DR
Nvidia have ended Linux support for my ‘Pascal’ GTX 1050 Ti GPU. I’ve been able to fit an RTX 5050 card in its place, though the process was problematic due to driver issues. And I’m still concerned that it can only be limited to 110W when my passive cooling is rated up to 75W.
Background
When I upgraded my silent PC earlier in the year I kept the original graphics card, with an Nvidia GTX 1050Ti. I couldn’t find anything better that fitted into the 75W power budget.
Then I saw Justin Garrison’s post linking to ‘NVIDIA Drops Pascal Support On Linux, Causing Chaos On Arch Linux‘.

I replied:
Grrr. I was considering options to upgrade the 1050Ti in my silent desktop, but nothing was compelling (mostly as Nvidia don’t do a 75W card any more).
Forced obsolescence sucks 🙁
It was clear that I was now on an obsolete platform, and I’d need a new card sooner or later. I decided to get the trouble out of the way before the Christmas break ended.
New card
A quick look at Quiet PC suggested that the Palit GeForce RTX 5050 StormX 8GB Semi-fanless Graphics Card would be the way to go. Unfortunately they were closed for Christmas.
Luckily Scan also had the card, and they were offering next day delivery. I opted to save £8.99 by not going for Sunday delivery, but (hurrah) it came on Sunday anyway. Top marks to Scan (and DPD) :)
Although it’s a 130W card, I found these instructions showing how to limit power usage – ‘Set lower power limits (TDPs) for NVIDIA GPUs‘.
I also ordered a 6pin to 8pin PCIe converter cable, as I knew my PSU didn’t have a newer GPU cable.
Cooling
Job 1 was to remove the heatsink and fan, which just needed a few screws to be taken out. I then set about swapping the DB4 GPU cooling kit from the old card to the new. Thankfully it was possible to do that without completely dismantling the PC. I was even able to leave everything apart from the display cables and power plugged in.
The mounting holes for the heat pipe cooler block were in the same spacing as before, and there was just enough space around the GPU. So no drama with this bit. I also had some heatsinks spare that I could attach to the RAM and other chips that were in contact with the OEM heatsink/fan arrangement.
Power
I’d bought the 6pin to 8pin converter knowing that I didn’t have an 8pin connector; but falsely thinking that the existing card used a 6pin.
It did not :( The old card just took power from the PCIe bus, which can supply the 75W it used.
There is a 6pin connector, but that goes to the motherboard.
So… I did this crime against cabling by sacrificing the SATA and Molex cables I don’t use and splicing their power to the adaptor cable I’d bought.

That got me to a system that would power up and show a screen, which is when the real fun began.
Drivers
As I already had an Nvidia card using their official drivers I expected the new card to ‘just work’. It did not.
I got a BIOS boot screen, and then the Kubuntu splash screen as it booted. But no login screen. Just a cursor blinking top left of an empty black screen.
Worse still, the keyboard driver was being disabled at some stage during boot, so I couldn’t just jump into a console and fix things from there.
When I tried unplugging the keyboard and plugging it back in again I got:
usbhid: couldn't find an interrupt endpointDisabling secure boot in the BIOS didn’t improve things.
Getting to grub
I needed to get to a console, which meant interrupting the regular boot.
According to many sources online all I needed to do was hold down (right) shift during boot. This accomplished nothing.
Next I tried hitting Esc. Unfortunately my repeated presses bounced me through the grub menu and into the grub command line. I needed to hit Esc, once, at precisely the right time.
On one of my failed attempts Esc got me the dmesg output during a regular boot, which revealed this gem:
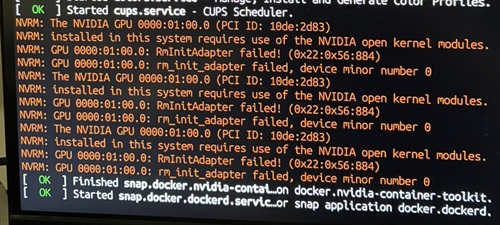
Eventually I hit Esc at just the right time, which let me boot into the console and uninstall the existing Nvidia drivers with:
apt purge ^nvidia-.*That got me a system that would properly boot. But only a single screen. I still needed the proper drivers:
sudo apt install nvidia-driver-580-open
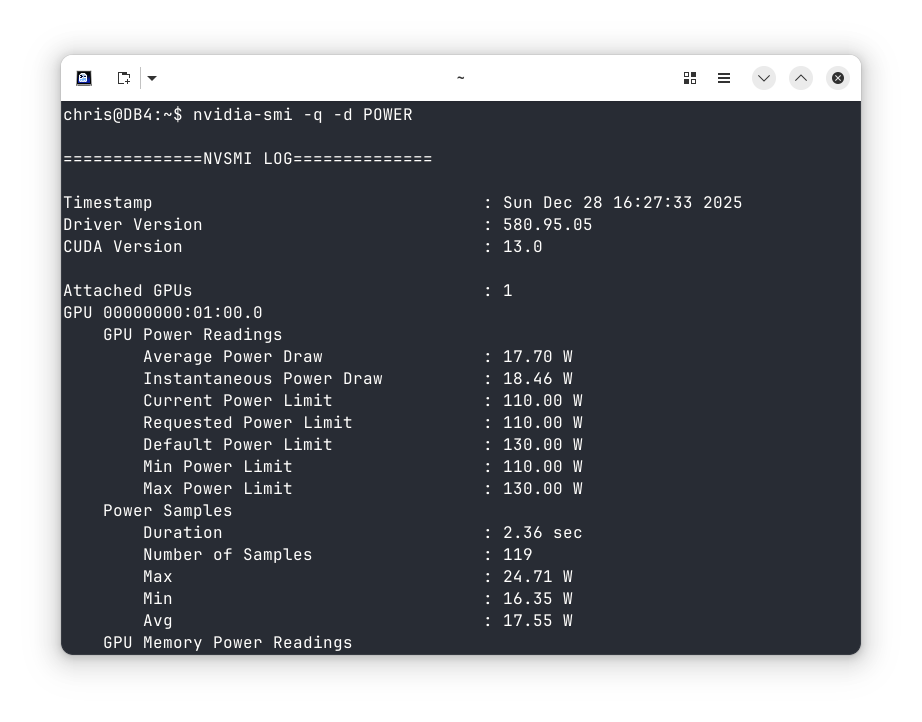
Finally… I was back to a proper multi monitor setup. All that remained was to configure power limiting. Unfortunately it turns out I can’t set things to 75W, as the lowest limit is 110W. On the other hand it does seem that quiescent power consumption is about half what the old card used to consume, so maybe I’ll save some pennies on my electricity bill :/
This could have gone much easier if…
- I’d known to uninstall the existing drivers first (and maybe even get the -open drivers in place)
- I’d reconfigured grub to make it easier to get into a console.
Performance (per watt)
I’ve not noticed any improvement in performance, but then I don’t generally use this PC for gaming.
According to GPU Monkey my old 1050 Ti scores 2mp or 0.0267mp/W.
The new 5050 scores 11mp, so 5.5x faster, but also consumes 130W to do that, so 1.73x more power. So only a 3.17x improvement in performance per Watt to give 0.0846mp/W.
Conclusion
This was an upgrade for necessity rather than something I really wanted. My daily use of the PC isn’t improved in any noticeable way.
I’m also a little concerned that I can’t limit the power to the rated capacity of the passive cooling, so if I ever do drive it hard with some gaming it’s likely to overheat and hit thermal throttling.
Filed under: howto, technology | Leave a Comment
Tags: 1050 Ti, 5050, console, cooling, drivers, GPU, grub, GTX, Kubuntu, Linux, NVidia, Palit, passive, power, RTX, silent, StormX
Milo’s had a fantastic long remission – it’s been almost nine months since his last chemo. Long enough that we started hoping for a miracle, and that he might not relapse again.

But… the good folk at North Downs Specialist Referrals (NDSR) were right to be concerned about his last scan, and get him back sooner than we’d originally planned. Although there are no signs of him being unwell, the lymph nodes are definitely growing :(
So… we’re back to weekly vet visits, for blood tests, and chemo if the bloods are looking OK. He’ll be doing the same modified CHOP protocol as last time – so Vincristine, Chlorambucil, Vincristine and Epirubicin over four cycles, along with some Prednisilone for the first few weeks.
Also… wow! I did not expect to still be adding entries to this diary (almost) three years later when I started in Jan ’23. Milo’s responded really well to past treatment, and we can only hope that keeps on going.
Past parts:
Filed under: MiloCancerDiary | Leave a Comment
Tags: cancer, chemo, chemotherapy, Chlorambucil, CHOP, Epirubicin, Milo, NDSR, Prednisilone, protocl, relapse, remission, Vincristine

