‘Filter failure at the outrage factory’ is a term I’ve been using on Twitter[1], usually as part of a quote tweet for something describing the latest social media catalysed atrocity, but I thought it deserved a longer form explanation, hence this post.

I fear that I buried the lede in a note when I first published this. But the core point is that Rule 34 (if it exists there is porn for it on the Internet) is being weaponised against the general population. The people out past (what should be) the 5th standard deviation are very into their peculiar peccadilloes, and that looks like ‘engagement’ to the algorithms.
The Outrage Factory
This is a label I’m going to smear across the entire advertising funded web, but the nexus of the issue is where traditional media and its previously trusted brands intersects with social media. The old sources of funding (subscriptions and classifieds) dried up, and that drove media companies into the arms of online advertisers, which quickly became a race to the bottom for our attention. Click bait headlines, fake news, outrage – they all get attention. Facebook, and YouTube and all the rest run off algorithms that finds the stuff that grabs and holds our attention, and those algorithms have discovered that outrage == $$$. Unfortunately those algorithms don’t care whether the material they hype is based on truth or some conspiracy theory nonsense or just an outright falsehood.
Filter Failure
Clay Shirky famously said [2] “It’s not information overload. It’s filter failure.” when describing how we could deal with the fire hoses of information the Internet can throw at us. At the time (2008) we were seeing the beginning of a shift from hand selected filters such as the RSS feeds one might subscribe to in Google Reader to ‘collaborative filters’ where we started to use the links posted by friends, colleagues and trusted strangers on Facebook and Twitter. Notably those were the days before algorithmic feeds.
The problem that developed from there is that where we thought we were handing curation over to our ‘friends’ we ended up handing curation over to the attention economy[3]. JP Rangaswami laid out Seven Principles for filtering, and it seems what we have today fails on all counts – we lost control.
Why care?
We should care because our democracy is being subverted. The checks and balances that worked in the world of print, radio and TV have proven utterly ineffective, and bad actors like the Internet Research Agency (IRA) are rampantly exploiting this to undermine our society[4].
We should care because dipshit stuff like the anti-vax movement that used to be consigned to wingnuts on the fringe of society has been sucked into the mainstream to the extent that it’s ruining herd immunity and we’re having life threatening and life changing outbreaks of completely preventable diseases.
We should care because algorithmically generated garbage is polluting the minds of a whole generation of kids growing up with iPads and Kindles as their pacifiers.

We should care because our kids are finding themselves a click or two away from Nazi propaganda, the Incel subculture, and all manner of other stuff that should be found somewhere out past the 5th standard deviation in any properly functioning society rather than being pushed into the mainstream.
We should care because this is the information age equivalent of the Bhopal disaster, and the Exxon Valdez, and the Great Molasses Flood, where toxic waste is leaking out and poisoning us all.
What can we do?
We don’t have to play along and sell our attention cheaply.
A wise friend once tweeted ‘I predict that in the future, “luxury” will be defined primarily by the lack of advertisements’. So upgrade your life to a life of luxury. Leave (or at least uninstall) Facebook. Install an ad blocker. Curate you own sources of information on something like Feedly.
Update 23 Apr 2019
I’ve been tracking items relating to this with the ffof tag on Pinboard.in
Update 25 Apr 2019
Sam Harris’s ‘Making Sense’ podcast interview with ‘Zucked‘ author Roger McNamee ‘The Trouble with Facebook‘ provides an outstanding tour around this topic.
Update 22 Feb 2020
Aral Balkan came up with a great contraction of aggro and algorithm:
Aggrorithm (n): an algorithm written to incite aggression.
Aggrorithms are a dark pattern employed by businesses with bottom lines tied to confrontation and conflict (“engagement”). Profiling data is used to nudge users into conflict and increase revenue.
Update 21 Oct 2020
Another Sam Harris podcast, this time with Tristan Harris – ‘Welcome to the Cult Factory‘
Notes
[1] About not amplifying outrage, listening at scale, outrage amplification as part of the system design, and recommendation engines pushing anti-vax onto new parents
[2] “It’s Not Information Overload. It’s Filter Failure.” Video, Clay Shirky at Web 2.0 Expo NY, Sept. 16–19, 2008.
[3] Aka ‘surveillance capitalism‘
[4] Renée DiResta‘s Information War podcast with Sam Harris is a good place to start, and then maybe move on to The Digital Maginot Line.
Filed under: wibble | 2 Comments
Tags: filter, news, outrage, social media
Skills development and training is a huge part of driving an organisation forward into the future, and so it’s something that I spend a lot of time and energy on. I’ve seen a bunch of stuff over the past year that leads me to expect a revolution in training.
Katacoda
![]()
I first came across Katacoda at RedMonk‘s Monkigras conference a couple of years ago when Luke Marsden showed me the Weave.works Tutorials he’d been building; and I immediately fell in love with the openness and interactivity of the platform. I’d seen training before that simulated a real world environment, but nothing that provided an authentic on demand experience[1].
I spent the following months creating what became ‘DevOps Dojo White Belt’ taking the ‘Infrastructure as Code Boot Camp’ materials we’d used for in person workshops and making it into something that could scale a lot better[2].
It was much more recently that I saw the full potential of Katacoda realised. The team that created our ‘DevOps Dojo Yellow Belt’ incorporated Continuous Integration and Continuous Delivery (CI/CD) pipelines in such a way that we could test whether students were achieving specific outcomes.
Qwiklabs

After attending a Google Cloud Derby hosted by Ant Stanley under the auspices of the London Serverless Meetup I was sent an invite to some Google Cloud Platform (GCP) training on the Qwiklabs platform (that was recently acquired by Google).
Specifically I was invited to do the GCP Architecture Challenge, which turned out to be like no training I’d ever done before. As explained in the ‘quest’ intro: ‘Challenge Labs do not provide the “cookbook” steps, but require solutions to be built with minimal guidance’…’All labs have activity tracking and in order to earn this badge you must score 100% in each lab.’
I found it was like doing an escape room. Each lab would describe an outcome that needed to be achieved, and it was up to me to figure out how to do that (using the tools provided), against the clock. Perhaps I should have done some training first, but it was really fun to learn stuff on the fly, solve the puzzle, and escape from the room lab before the clock ran down.
Open book (it’s OK to use Google and Stack Overflow)
The emergent point here is that students shouldn’t expect to be spoon fed every minute detail – they’re expected to go and read the docs, dive into Stack Overflow, search for answers on Google and in GitHub, maybe even watch some YouTube primers. Real life is an open book test, so training should reflect that.
Exercism
I saw this outcome oriented theme continue when a colleague pointed me towards Exercism yesterday. It provides training for a wide variety of programming (and scripting) languages with a common underpinning that it’s all based on tests. Just like with test driven development (TDD) you write code to pass the test suite. This results in a stunning variety of working results that can be seen from other people’s submissions, which are worth reviewing to discover everything from language idioms to significant performance improvements. Students can edit the tests too, adding things that might have been missed. It’s a really neat way of learning a language and at the same time getting into the discipline of TDD.
Codecademy, Microsoft Learn and The Hard Way
I can’t finish without a nod to these:
I started using Codecademy when it first launched, and put up with the early wrinkles because it was so beautifully immersive. I was lured back in the past week by their Learn Vue.js course (after seeing Sarah Drasner showing off the potential of Vue.js in her Servless Days London talk[3]), and it was great (the course and Vue.js) – though I can’t say I’m keen on the cost of their ‘Pro’ subscription model.
When I saw Microsoft launch Learn at Ignite 2018[4] my first take was ‘they’ve totally ripped off Katacoda’, but that was quickly followed by being seriously impressed at how well they’ve incorporated on demand subscriptions for the underlying Azure services it provides training for. There’s some seriously good introductory material there, and I hope over time they’ll close the gap to meet up with Azure certifications.
‘The Hard Way‘ isn’t so much a platform as a methodology designed to get ‘muscle memory’ into students, and show them the essential details that often gets buried under layers of abstraction (but matters when things fall apart). I first came across it with Kelsey Hightower‘s Kubernetes The Hard Way, and got pulled deeper with Ian Miell‘s Learn Git/Bash/Terraform The Hard Way, though it’s worth noting that it all started with Zed A. Shaw.
Conclusion
The future of IT training is interactive and outcome oriented. Rather than being spoon fed a particular way to do something we can expect to be given open platforms that allow experimentation (and provide a safe place to try things out), and open challenges that test our ability to solve problems with the entire resources of the Internet at our hands (just like when we’re putting knowledge to use at work). If we want people to use TDD and build CD pipelines, then it should be no surprise that those same tests and pipelines can form an essential part of their skills development. The good part is that this unleashes unlimited creativity, because people can figure out their own way to achieve an outcome; and approaches can be compared with peers and mentors to discover how things might be improved. It’s a long way from passively sitting in a classroom, or watching a video.
Update 22 Mar 2021
‘Last Week in AWS‘ curator Corey Quinn (@quinnypig) wrote about his experiences with an AWS Beta Certification Exam, which includes some thoughts about the use of labs and open book experiences.
Meanwhile I’ve had my first really bad experience with QwikLabs. Google has been running a promotion for ‘skills challenge‘, which gets participants a free month on Qwiklabs, and they seem to be doing different featured challenges each month, so in total that’s 5 months of free Qwiklabs if you started back in January. This month’s featured skills challenge is Kubernetes, and part of that is the ‘Secure Workloads in Google Kubernetes Engine‘ Quest, which has the ‘Secure Workloads in Google Kubernetes Engine: Challenge Lab (GSP335)’ at the end. I’ve had five attempts at getting through that Challenge Lab, and they’ve all failed because the lab itself has been broken in one way or another. Initially I just couldn’t get WordPress to successfully authenticate to Cloud SQL, and once that was fixed I found myself (along with many others judging by the feedback) hitting problems with rate limits at Lets Encrypt. I guess it’s not such a good idea to dogpile a free service by having a promotion that sends all your students that way. And now I’m locked out because I’ve hit ‘Sorry, your quota has been exceeded for this lab’
Notes
[1] For me the best demo of Katacoda is the 10 minute beginner level ‘Get Started with Istio and Kubernetes‘ – there’s just so much packed into it.
[2] At the time of writing over 10,000 DXCers have done the White Belt.
[3] I can’t find a recording of that talk, but her VueConf.US talk ‘Serverless Functions and Vue.js‘ seems pretty similar.
[4] I wasn’t actually at Ignite (I’ve never been) – it just seems to me that Learn is by far the most important thing that came out of the 2018 event.
Filed under: DXC blogs, technology | 2 Comments
Tags: Codecademy, Exercism, GSP335, Katacoda, Microsoft Learn, outcomes, Qwiklabs, TDD, training
TL;DR
Getting a Midas Plus squirting properly again is very easy once you learn the secret of removing and cleaning the thermostatic cartridge. A simple procedure due to some great design, but one that isn’t documented anywhere that I could find.
Background
In just over a year since I had a new shower fitted as part of an en-suite refurb it went from ‘Oh yeah!’ to ‘meh’. I’ve had Aqualisa showers at home for over 20 years, which I guess makes me a loyal customer, but in that time I’ve needed a few replacement thermostatic cartridges – generally because the flow rate has become a bit useless.
Checking filters
The trouble shooting guide in the installation instructions suggests three possible causes for poor flow rate – twisted hose, debris in shower head, and debris in filters, with ‘check and clear as necessary’ as the action to take. I knew it wasn’t the first two, as flow was fine if I turned the thermostat to cold. So I set about checking the filters, which meant taking the mixer bar off its mount.
- First I turned off the water supply
- Then I taped over the fixing nuts with electrical tape (as they’re shiny stainless steel, and I didn’t want to scratch them with my dirty old adjustable spanner [they’re 29mm, and I don’t have a regular spanner that big])
- After loosening the nuts I was able to pull the mixer bar away and remove the filters. The cold filter was clear, but the hot filter did have quite a large crystal deposit in it, which I rinsed off with a jug of water.
All of this made absolutely no difference. The shower flow rate was still poor.
The cartridge
I called the Aqualisa support team for help, and after talking through the problem they offered to send me a replacement thermostatic cartridge. This led to a follow on question from me about how to fit it once it arrived? The support person said to follow the installation guide, but I’d already been through that, and it makes no mention at all of cartridge removal and replacement. She then told me to start by taking the end cap off the control. When I went and tried that I soon discovered that isn’t how to get the cartridge out.

Picture of cartridge from Aqualisa website
I then did what I perhaps should have done in the first place. I took to YouTube, and found this video ‘Thermostatic cartridge: maintenance, replacement and calibration‘, which showed me that the cartridge is held in by a (very well hidden) grub screw on the bottom of the mixer bar. All I had to do was:
- Turn off the water supply (IMPORTANT – the water on/off on the left hand side of the bar simply acts on the cartridge, so if you take it out without isolating the supply first the cartridge will fly out and then water will gush from the mixer bar).
- Undo the grub screw on the bottom right hand side of the mixer bar with a 3mm hex bit

- Pull the cartridge out
- Rinse away any debris using a jug of water

Other side of cartridge showing where grub screw fits
Once I popped the cartridge back in the shower was as good as new.
Crucially there was no need to remove the end cap and mess around with the thermostatic calibration.
I have questions
Once you know where the grub screw is, the simplicity of removing and refitting the cartridge stands out as a wonderful piece of design. Somebody thought very hard about how to make this as easy as possible; and then somebody else decided to exclude any mention of the grub screw and the cartridge from the instructions. Given that in the past Aqualisa have provided detailed instructions for the much more complex process for removal and refitting of earlier designs it seems really odd that they managed to make everything so much better, then chose to keep the details to themselves. This must result in a higher than needed support burden, and associated drag on profitability, which I find utterly bizarre.
Also the filters on the cartridge itself are (by my estimation) finer than the main inlet filters. So ‘check and clear’ for the filters should definitely mean both the inlet filters and the filters around the cartridge itself. Again I’m guessing that’s by (very good) design, and then somewhere else a decision has been made to withhold crucial information :/
Filed under: howto | 2 Comments
Tags: Aqualisa, cartridge, flow, Midas, Plus
Cloudflare recently announced two additional capabilities for their “serverless” Workers: support for WebAssembly as an alternative to JavaScript, and a key-value store called Workers KV. WebAssembly will allow Workers to be written in compiled languages such as C, C++, Rust and Go. Workers KV provides an eventually consistent state storage mechanism hosted across Cloudflare’s global network of over 150 data centres.
Filed under: cloud, InfoQ news | Leave a Comment
Tags: cloud, CloudFlare, FaaS, KV, stateful, WASM, WebAssembly, Workers
Multi Cloud Governance
This is one of those posts that started life on an email thread. It comes from a discussion on the topic of multi cloud governance for large enterprises.
Why cloud?
The answer is not ‘cloud is cheaper’, because it just isn’t. We know from Amazon’s financials that it’s gushing money because cloud is a high margin and very profitable business. Any halfway competent large enterprise can run its own data centres cheaper, and the mainframe and midrange legacy isn’t going anywhere so neither are those data centres.
The answer is ‘cloud is faster’. Cloud enables quicker delivery of value in response to changing user needs. ‘Digital’ is built out of continuous delivery (CD) pipelines, and CD pipelines need cloud at the end of them, because you can’t do continuous delivery without API enabled on demand infrastructure (which is lots of words for ‘a cloud’).
What kind of cloud?
Having focused our attention on the right category – applications that deliver outcomes more quickly by constructing CD pipelines – we finally come to the vexed question of what type of services do they want to consume? Is it IaaS, CaaS, FaaS (or some combination)?
Safety First
The crucial outcome is safety[1]. The app developers need to be able to consume services without crossing lines with respect to security and compliance.
Safety costs money (but far less than unsafe practices) so we end up at a cost/benefit trade off. For every class of services that consumed how much does it cost to make them safe, and what benefit is accrued (in speed to market and revenue achieved from that)? This doesn’t just apply to which cloud will be used (AWS vs Azure vs Google); it also applies at a finer grained level to which services are consumed within those clouds.
Control vs Productivity
Most large enterprises are looking down the wrong end of the telescope. They’re thinking about control before productivity rather than productivity before control; and that pattern is borne from the traditional enterprise mindset of standardisation to reduce complexity and cost.
Many enterprises feel like they have these options:
- Make the complexity appear to go away by putting a unifying broker layer between the cloud and its consumer.
- Accept that there will be multiple data centres and cloud providers and use some sort of common technology (e.g. containers) to enable common approaches to application development and deployment.
- Some combination of (1) and (2) where elements of the infrastructure and operations are treated in a common way (e.g. billing, operational data, software delivery).
None of them are good, because all of them presuppose that we make an activity safe before we even know what the activity is. It’s a great way of spending time and treasure on something that never delivers any practical value[2].
Getting to the cost/benefit trade off
This means actually knowing the cost, and actually being able to figure out the benefit. A managed cloud service with safety built in (like you get from a services company rather than the raw cloud underneath it) will show a sticker price for cost – so we’re half way there. The other half naturally extends into the enterprise’s own investment appraisal processes (and there’s room for services companies to be facilitators for the extra work needed there).
In the end it doesn’t matter whether they use one cloud or five. Whether they use containers, functions or VMs. It only matters that engineers are safe, and the overhead of achieving that safety is part of the broader business case for the functionality.
The final issue is the classic ‘buy the restaurant to eat the first meal’ problem that so often comes up with large enterprises, where any given app can’t make the business case stand up on its own. That takes us to a portfolio management exercise where the investment in safety for a category of apps with common needs gets justified by the expected benefits of all those apps (and the apps that might follow them). So there’s a need for some degree of aggregation. What happens next is essentially paving the cow paths – early success becomes the path of least resistance for things that follow (so that they don’t have to make fresh cases for their own new safety demands).
What this brings us to is the ability to say to application developers ‘you can have anything you want provided that you can afford the safety’, ‘you may club together to pay for safety’. That leads to an initial cohort of apps that make something happen within the confines of a given set of safety systems. It’s easy to follow them, because the safety investment has already been paid down. Apps can choose not to follow, but that choice comes with the consequence that they need to stand up their own safety and pay the premium.
They key point is ‘they come and we build it’ rather than ‘build it and they shall come’.
Notes
[1] I’ve written about safety (first) before.
[2] For more on why brokers are considered an anitpattern take a look at Barclays’ Infrastructure CTO Keiran Broadfoot in his 2017 re:Invent presentation.
Filed under: cloud | Leave a Comment
Tags: agility, CD, cloud, continuous delivery, cost, enterprise, governance, safety, speed
Our expectations for user experience are shaped by the huge consumer platforms such as Google, Apple, Facebook and Amazon, and also the devices that we access them with such as iPhones, iPads, Android phones and tablets, and the PCs or Macs we use at home.
When we use these consumer devices and services, there’s no help desk for issues that come up, but in general there’s also no need for a help desk because the devices “just work.” That’s the type of user experience organisations strive for on their journey to digital.
Filed under: DXC blogs | Leave a Comment
Tags: Bionix, consumerisation, digital, GAFA
Raspberry Pi Sous Vide Redux
TL;DR
My hardware and software setup for my Raspberry Pi sous vide setup have remained the same for over 5 years, but a failed remote controlled socket forced me to update almost everything.
Background
The Maplin remote control socket would turn on, and briefly supply power to the slow cooker, but then it would appear to trip. This wasn’t the first time, as the original socket failed after a few years, but this time there’s no chance of getting a replacement from Maplin as they’ve gone out of business.

A1210WH
After a bit of hunting around I tried ordering a Lloytron A1210WH socket set, as it looked identical to the Maplin one (and hence was likely to have come from the same original equipment manufacturer), but the package I received had the newer model A1211WH.

A1211WH
I could have returned them in the hope of getting some of the older ones from elsewhere, but I decided to bite the bullet and just make things work with the new ones.
Blind Alley
I had a go at using 433Utils, which was able to read different codes from the new remote with RFSniffer, but sending those codes using codesend just didn’t work (and didn’t even show the same code being played back on RFsniffer).
pilight
How I Automated My Home Fan with Raspberry Pi 3, RF Transmitter and HomeBridge had a similar issue with 433Utils, and used pilight to read codes from his remote then send them out from a Pi controlled transmitter.
Here began a bit of a struggle to get things working. My ancient Raspbian didn’t have dependencies needed by pilight, so I burned a new SD card with Raspbian Stretch Lite (and then enabled WiFi and SSH for headless access).
My initial attempts to use pilight-debug crashed on the rocks of missing config:
pilight no gpio-platform configured
In retrospect the error message was pretty meaningful, but Google didn’t help much with solutions, and all of the (pre version 8) example configs I’d seen didn’t have the crucial line for:
gpio-platform: "raspberrypi1b1"
That raspberry version maps to the options for the WiringX platform that sits within pilight.
With the config.json sorted for my setup (GPIO 0 to transmitter, and GPIO 7 to receiver [as a temporary replacement for the 1Wire temperature sensor]) I was able to capture button presses from the remote control. It quickly became apparent that there was no consistency between captures, and I’m guessing the timing circuits just aren’t that accurate. But the patterns of long(er) pulses to short(er) pulses were consistent, so I extracted codes that were a mixture of 1200us, 600us and a 7000us stop bit (gist with caps, my simplification, and generated commands).
Success
With timings in hand I was able to turn the new sockets on and off with pilight-send commands in shell scripts for on and off. It was then just a question of updating my control script to invoke those rather than the previous strogonanoff scripts (having migrated my entire sousvide directory from old SD to new via a jump box with a bit of tar and scp).
Filed under: Raspberry Pi | Leave a Comment
Tags: 433MHz, config.json, GPIO, pilight, remote control, Sous vide
In Plain Sight
“The future is already here — it’s just not very evenly distributed.” – William Gibson
This post is about a set of powerful management techniques that have each been around for over a decade, but that still haven’t yet diffused into everyday use, and that hence still appear novel to the uninitiated.
Wardley Maps
Simon Wardley developed his mapping technique whilst he was CEO at Fontango.
A Wardley map is essentially a value stream map, anchored on user need, and projected onto a X axis of evolution (from genesis to commodity) and a Y axis of visibility.
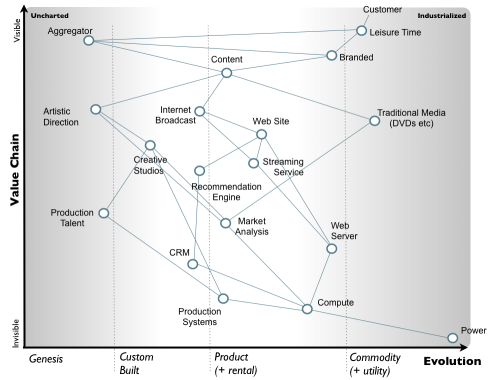
The primary purpose of a Wardley map is to provide situational awareness, but they have a number of secondary effects that shouldn’t be ignored:
- Maps provide a communication medium within a group that has a pre determined set of rules and conventions that help eliminate ambiguity[1].
- Activities evolve over time, so map users can determine which activities in their value chain will evolve anyway due to the actions of third parties, and which activities they choose to evolve themselves (by investment of time/effort/money).
- Clusters of activities can be used to decide what should be done organically within an organisation, and what can be outsourced to others.
Working Backwards
Amazon’s CTO Werner Vogels wrote publicly about their technique of working backwards in 2006, and the origin stories of services like EC2 suggest that it was well entrenched in the Amazon culture before then[2].
The technique involves starting with a press release (and FAQ) in order to focus attention on the outcome that the organisation is trying to achieve. So rather than the announcement being written at the end to describe what has been built, it’s written at the start to describe what will be built, thus ensuring that everybody involved in the building work understands what they’re trying to accomplish.
A neat side effect of the technique is that achieveability gets built in. People don’t tend to write press releases for fantastical things they have no idea how to make happen.
Site Reliability Engineering (SRE)
class SRE implements DevOps
SRE emerged from Google as an opinionated approach to DevOps, eventually as a book. Arguably SRE is all about Ops, complementing Dev as practiced by SoftWare Engineers (SWE); but the formalisation of error budgets and Service Level Objectives (SLOs) provides a very clean interface between Dev and Ops to create an overall DevOps approach.

SRE isn’t the only way of getting software into production and making sure it continues to meet expectations, but for organisations starting from scratch it’s a well thought through and thoroughly documented approach that’s known to work (and with a pre fabricated market of practitioners); so the alternative of making up an alternative seems fraught with danger. It’s no accident that Google’s using SRE at the heart of its Customer Reliability Engineering (CRE) approach where it crossed the traditional cloud service provider shared responsibility line to work more closely with its customers[3].
Pulling it all together
These techniques don’t exist in isolation. Whilst each is powerful on its own they can be used in combination to greatly improve organisation performance. Daniel Pink’s Drive talks about Autonomy, Mastery and Purpose in terms of the individual, but at an organisation level[4] they might fit like this:
- Autonomy – Wardley maps provide a way to focus on the evolution of a specific activity, and with that determined the team can be left to figure out their way to achieving that.
- Mastery – SRE gives us a canned way to get software into a production environment , making it clear which better skills are needed and must be brought to bear.
- Purpose – the outcome orientation that comes from working backwards provides clarity of purpose, so nobody is in doubt about what they’re trying to accomplish.
Notes
[1] I commonly find that when I introduce Wardley mapping to senior execs their initial take is ‘but that’s obvious’, because they internally use something like the mapping technique as part of their thought process. I then ask them ‘do you think your entire team shares your views of what’s obvious?’.
[2] Arguably a common factor for many of these approaches is that they become public at a point where the companies they emerged from have determined that there’s nothing to lose by talking about them. In part that’s down to inevitable leakage as staff move on and take ways of working with them, and in part it’s because it does take so long for these techniques to find widespread use amongst potential competitors.
[3] A central argument here is that achieving ‘4 nines’ availability on a cloud platform is only possible when the cloud service provider and customer have a shared operations model, and sharing operations means having a mutually agreed upon mechanism for how operations should be done.
[4] An organisation might be an Amazon ‘2 pizza’ team, or an entire company.
Filed under: culture | 2 Comments
Tags: DevOps, management, maps, SRE, Wardley, working backwards
Silent PC
TL;DR
I’ve been very happy with the silence of my passively cooled NUC for the past 4 years, but it was starting to perform poorly. So when I came across a good looking recipe for a silent PC with higher performance I put one together for myself.
Background
I’ve been running my NUC in an Akasa silent case since shortly after I got it, and it’s been sweet, until it wasn’t. Silence is golden, but having a PC that’s constantly on the ragged edge of thermal limiting for the CPU and/or SSD[1] became pretty painful[2]. When I came across this Completely Silent Computer post a few weeks back I knew it was exactly what I wanted[3].

Parts
I pretty much followed Tim’s build, with a few exceptions:
- I went for the black DB4 case
- In line with his follow up Does Pinnacle Ridge change anything? I went with the Ryzen 5 2600 CPU
- The MSI GeForce GTX 1050 Ti Aero ITX OC 4GB was available, so I went with that
- A Samsung 970 SSD (rather than the 960)
Unfortunately I wasn’t able to get everything I needed from one place, so I ended up placing three orders:
- QuietPC for all the Streacom stuff (DB4 case, CPU and GPU cooling kits and PSU)
- Overclockers for the motherboard, SSD and CPU
- Scan for the RAM and GPU
By some miracle everything showed up the following day (with the Scan and Overclockers boxes coming in the same DPD van). The whole lot came to £1551.34 inc delivery, which is a bit better than the AUD3000 total mentioned in the original post. I didn’t exhaustively shop on price, so it’s possible I could have squeezed things a little more.
Testing, testing
There aren’t that many components, and they only work as a whole, so I put it all together and (of course) it didn’t work first time. The machine would power on, but there was no output from the graphics card.
There was nothing to go on for diagnostics other than that the power button and LED were apparently working.
So I had to pretty much start over, with everything laid out on a bench, and I found that the CPU wasn’t seated properly. I guess having such a complex heat pipe system attached puts a fair bit of mechanical force onto things that can dislodge what seemed like a sound fit.
As I was checking things out I also noticed that the SSD was perilously close to a raised screw hole on the motherboard holder, which I chose to drill out – better safe than sorry.
Putting it back together I retested after each stage in the construction (each side of the case in terms of heat transfer arrangements), and everything went OK through to completion.
It’s fast
Geekbench is showing a single core score of 4329 and a multi core score of 20639.
That’s way ahead of my NUC which managed 2420 and 4815 respectively. It even beats my son’s i5-6500 based gaming rig that clocked 3208 and 8045.
Cool, but not super cool
As I type the system is pretty much idle, but I’m seeing a CPU temperature in the range of 57-67C, which is nothing like the figures Tim got when measuring Passively-cooled CPU Thermals. The GPU is telling me it’s at 48C. There are a few factors that come into play here:
- It’s baking in the UK at the moment, so my ambient temperature is 28C rather than 20C.
- One of the Streacom heat pads was either missing or got lost during my build, so I’m waiting on another to arrive. Thus the thermal efficiency of the CPU cooling isn’t presently all it could be.
I’d also note that I went with the LH6 CPU cooling kit despite having no plans to overclock as I’d like to keep everything as cool as possible.
The case temperature is around 40C, so hot to the touch, but not burning hot. In the winter I might appreciate the warmth it radiates, but right now I’d rather have it off my desk.
Cable management
The DB4 case design has everything emerging from the bottom, which might look amazing for photos when it’s not plugged into anything, but is far from ideal for actual usage. I’ve bundled the cables together and tied them off to the stand, but this is not a machine that makes it easy to pop things into. There are a couple of USB ports on one corner (which I’ve arranged as front right), but using them is a fiddle.
I’m pleased to have USB ports on my keyboard and a little hub sat on my monitor pedestal.
Conclusion
After using a silent PC for over 4 years there’s no way I’d go back to the whine of fan noise, so I was pleased to find an approach that kept things quiet whilst offering better performance. The subjective user experience is amazing (this is easily the fastest PC I’ve ever used), so my fingers are crossed that it stays that way.
Notes
[1] There’s not much talk about thermal throttling of SSDs, but it is a thing, and it can badly hurt user experience when your writes get queued up. I do worry that my new M2 drive is sat baking at the bottom of the new rig, and if I find myself taking it apart again I might stick a thermal pad in place so that it can at least conduct directly onto the motherboard tray.
[2] I suspect that over the years the Thermal Interface Material (TIM) in the CPU degraded, leading to the whole rig running hotter, leading to a spiral of poor performance. When it was new it ran quick enough, and (relatively) cool, but it seems over time things got worse.
[3] I considered another NUC, and the Hades Canyon looks like it would have met my needs, but Akasa don’t yet do a silent case for it.
Filed under: technology | 5 Comments
Tags: AMD, benchmark, DB4, NUC, PC, Ryzen, silent, Streacom, temperature, thermal
The Constraint Unblocker
#2 of jobs that should exist but don’t in most IT departments (#1 was The Application Portfolio Manager).
What’s a constraint?
From Wikipedia:
The theory of constraints (TOC)[1] is an overall management philosophy introduced by Eliyahu M. Goldratt in his 1984 book titled The Goal
It’s the idea that in a manufacturing process there will be a constraint (or bottleneck) and that:
- there’s no point in doing any optimisation work before the constraint, because that will just make work in progress stack up even quicker
- there’s no point in doing any optimisation work after the constraint, because the work in progress is still stuck upstream
TOC drives us towards a singular purpose – identify the present constraint and fix it.
Of course this becomes a game of ‘Whac-A-Mole‘, just as soon as one constraint is dealt with another lies waiting to be discovered. But it’s an excellent way of ensuring that time, money and other resources are focused in the right place, and the starting point for continuous improvement that takes advantage of incremental gains.
The constraint unblocker
Is an individual who’s empowered to work across an organisation identifying its constraints and leading the efforts to fix them.
James Hamilton
One of my industry heroes is Amazon’s constraint unblocker – James Hamilton[2]. He has:
- Reinvented data centre cooling (and many other aspects of data centre design)
- Reinvented servers
- Reinvented storage
- Reinvented networks
- Modified power switching equipment
Take a look at his AWS Innovation at Scale presentation for some depth, or the Wired article Why Amazon Hired a Car Mechanic to Run Its Cloud Empire.
The consequence of that list above shouldn’t be underestimated. Where Hamilton (and his like at Google, Facebook etc.) have led, the entire industry has followed.
The impact of that list shouldn’t also imply that there’s no point in doing this elsewhere. This approach isn’t just the preserve of hyperscale operators. All IT shops have their constraints, and so all IT shops should have a leader who’s focused on unblocking them.
TOC and DevOps
There’s a close relationship between TOC and DevOps. The Goal inspired The Phoenix Project and the ‘3 DevOps Ways’ of Flow, Feedback and Continuous Learning by Experimentation are all about dealing with constraints.
That isn’t however to say that organisations doing DevOps have everything covered. The 3 ways make sure that constraints are addressed in the context of a single continuous delivery pipeline for a single product, but as soon as there’s more than one product there’s most likely a global constraint that can’t be dealt with at a local level.
Amazon may be doing DevOps up and down the organisation, and they very effectively organise themselves into ‘2 pizza‘ teams ‘working backwards‘ building micro services to power their ever expanding service portfolio. But they still need James and his team working top down to get the big roadblocks out of their way as they spend $Billions scaling their infrastructure.
Data (science) required
Notionally this stuff was easy with manufacturing. Look down on the factory floor and you can see the workstation where the work in progress is stacking up. Pop down there and figure out how to fix it.
Of course the reality was much messier than that, which is why Goldratt quickly found himself revising The Goal, and a whole consulting industry sprang up around TOC. But with software we have to acknowledge from the outset that we’re not going to see work in progress physically piling up; and beyond DevOps it’s entirely possible that the constraint may have little to do with ‘work in progress’.
Thus in IT we need data to find our constraints, and we usually need that same data (or more) to inform the model-hypothesise-experiment process that determines what to do about a constraint. In my own work (that we now brand Bionix) that’s why we start with the data science team and their analytics.
Why bother?
My personal observations of TOC in action over the past few years have generally found a 20% improvement in efficiency/effectiveness on the first iteration. That’s not moving the decimal disruption, but that’s a realistic first approximation of what’s achievable in a six week cycle.
Of course because this is Whac-A-Mole you never get the same pay off again. The next iteration might be 15%, then 12%, then 9% and quickly off into the weeds. But stack those gains on top of each other and you’re quickly into completely different territory.
Conclusion
As we can see from Amazon even the best organisations have constraints, and they can benefit from having a leader focused on identifying and fixing them. That way they can achieve continuous improvement and the fruits of incremental gains across the organisation, and not just in a product silo.
Notes
[1] I find it somewhat frustrating that ‘theory’ is used here as it makes the approach seem ‘academic’ and thus easily dismissed by those claiming that they only care about practical outcomes.
[2] James starred in my ScotCloud keynote last year “Our problems are easy“.
Filed under: technology | Leave a Comment
Tags: amazon, aws, constraint, DevOps, Goldratt, James Hamilton, The Goal, The Phoenix Project, theory of constraints, TOC, unblock

