In a footnote to yesterday’s application intimacy post I said:
in time there will be services for provisioning, monitoring and logging, and all that will remain of ‘infrastructure’ will be the config of those services; and since we might treat that config as code then ultimately the NoOps ‘just add code – we’ll take care of the rest’ dream will become a reality. Barring any surprises, that time is likely something in the region of 5 years away.
That came from an extensive conversation with my colleague Simon Wardley on whether NoOps is really a thing. The conversation started at Serverlessconf London where I ended up editorialising the view that Serverless Operations is Not a Solved Problem. It’s worth pointing out a couple of things about my take on Simon’s perspective:
- Simon sees DevOps as a label for the (co-evolved) practices emerging from IaaS utilisation, and hence it’s not at the leading edge as we look to a more PaaS/FaaS future.
- Simon is a great visionary, so what he expects to come true isn’t the same as what’s actually there right now.
This whole debate was due to come up once again at London CloudCamp on 6 July at an event titled “Serverless and the death of DevOps“. Sadly I’m going to miss CloudCamp this time around, but in the meantime the topic has taken on a life of its own in a post from James Governor:
it’s a fun event and a really vibrant community, but the whole “death of devops” thing really grinds my gears. I blame Simon Wardley. 😉
Whilst not explicitly invoking Gene Kim and the ‘3 Ways’ of DevOps (Flow, Feedback and Continuous Learning by Experimentation); it seems that James and I are on the same page about the ongoing need to apply what manufacturing learned from the 50s onwards to today’s software industry (including Serverless).
Meanwhile Paul Johnston steps in with an excellent comment and follows up with a complete post ‘Serverless is SuperOps‘. In his conclusion Paul says:
Ops becomes your primary task, and Dev becomes a the tool to deliver the custom business logic the system needs.
I think that’s a sentiment born from the fact that (beyond trivial use cases) using Serverless right now is just the opposite of NoOps; the ops part is really hard, and ends up being the majority of the overall effort. There may no longer be a need to worry about VMs and OSes and patching and all of those IaaS concerns (that have in many cases been automated to the point of triviality); but there’s still a need to worry about provisioning, config management, logging and monitoring.
Something that Paul and I dived into recently are some of the issues around testing. Paul suggests ‘The serverless approach to testing is different and may actually be easier‘, but concludes:
we’re currently lacking the testing tools to really drive home the value.—looking forward to when they arrive.
I asked him, “How do you do canarying in Serverless?“, which led to a well thought through response in ‘Serverless and Deployment Issues‘. TL;DR canarying is pretty much impossible right now unless you build your own content router, which is something that’s right up there on the stupid and dangerous list; this is stuff that the platform should do for you.
Things will be better in the future. As Simon keeps pointing out the operational practices will co-evolve with the technologies. Right now Serverless is only being used by the brave pioneers, and behind them will come the settlers and town planners. Those later users won’t come until stuff like canarying has been sorted out, so the scope of what a Functions as a Service (FaaS) platform does will expand, and the effort to make things work will correspondingly contract. In due course it’s possible that if we look at it just right (and squint a bit) we could call that NoOps. Of course to do that we will have had to learn how to encode everything we want to do with provisioning, logging and monitoring into the (infrastructure as code) config management; we will have had to teach the machine (or at least the machine learning behind it) how to care on our behalf. Until then, as Charity Majors says – ‘you can’t outsource caring‘.
Filed under: cloud | Leave a Comment
Tags: DevOps, NoOps, serverless
This is another post that’s a recycled email, one which started out with the title: ‘Our share of the cloud shared responsibility model (and the need for application intimacy)’
The original email came from a number of discussions in the run up to the DXC merger, and I must thank many of my CTO and Leading Edge Forum (LEF) colleagues for their input. It was addressed to the Offering General Managers covering Cloud (for the infrastructure centric bottom up view) and Application Services (for the more top down connection of business need to application, which is nicely summed up in JP’s Business Experience Management paper).
TL;DR
The IT landscape in front of us will be all about the apps, and we need to get intimacy with those apps to earn our share of the cloud shared responsibility model.
Assumptions
To set the scene let me lay out some assumptions:
- The march of public cloud might look unstoppable right now because it’s in the early linear section of its adoption S curve, but it will stop. When it does stop it will have absorbed much of the workload that presently runs in our data centres and our customer’s data centres. The infrastructure revenue that we have associated with that is going away, never to return, and we’ll get crumbs from the AWS/Azure/GCP table where we can as the partner for the billing process.
- We will willingly engage in the movement of that workload to win our place as the partner in the billing process[1].
- The place that we earn our keep going forward is bridging the gap between what our customers want, and what the clouds actually deliver. For the time being there might be dreams of ‘NoOps’, but even in a world of Serverless functions it turns out that there’s still a need for provisioning, config management, monitoring and logging[2] – the things that we wrap up today as (integrated digital) service management. Our customers want NoOps, but it will be some time yet before they get it straight from a cloud provider, which is why they’ll turn to us.
Our Share of Shared Responsibility
The key here is something that we might call ‘application intimacy’. Doing what it takes to run an application (any application) requires a high touch contextual understanding of what the app is and does, when it’s performing well and performing badly, how it’s helping a business win or holding them back. Cloud service providers don’t do application intimacy, which is the whole point of their shared responsibility model. We generally talk about the shared responsibility model in the context of security, but it also extends into pretty much every aspect of operations. The shared responsibility model is the line where the cloud service provider says ‘our work here is done – your problem now’, and that’s where we step in because our customers still want that problem to be somebody else’s problem.
Clearly we can gain application intimacy forensically – it’s what we do within transition and transformation (T&T) for any IT Outsourcing (ITO); but there’s also an obvious opportunity to gain application intimacy organically – as we build apps from scratch or help customers (re)define their application construction and testing pipelines (aka CI/CD).
Application Intimacy
So… the call to action here is to orient our new company around application intimacy – it needs to be in the heart of our strategy, our messaging, our organisation, our offerings, our culture. If we can win at application intimacy then we take our share of the shared responsibility model, and earn a rightful place at the table alongside the cloud service providers.
Notes
[1] and right now the cloud providers see that they need our help – AWS is looking to drive 60%+ of their global business to GSIs who have differentiated offerings in the marketplace (e.g. app intimacy), strong vertical/ industry expertise, and c-suite relationships.
[2] in time there will be services for provisioning, monitoring and logging, and all that will remain of ‘infrastructure’ will be the config of those services; and since we might treat that config as code then ultimately the NoOps ‘just add code – we’ll take care of the rest’ dream will become a reality. Barring any surprises, that time is likely something in the region of 5 years away.
Filed under: cloud, DXC, DXC blogs | 1 Comment
Tags: cloud, DevOps, operations, serverless
The DXC Blogs – outro
I just had to Google ‘outro‘ to confirm it’s actually a word (as the Chrome spellcheck thinks not).
Yesterday marked the end of the back catalogue of posts that I’d originally made on C3, so it’s back to normal service here on the blog.
If you’d like a list for this series of posts then check out the pingbacks to the intro post.
Filed under: DXC blogs | Leave a Comment
Originally posted internally 13 Dec 2016, this post marks the end of my journey through the back catalogue:
The dust has hardly settled from re:Invent, but today brings the first big public launch since AWS’s big annual event – AWS Managed Services.
This will be one of those blog posts that I hope saves me having to repeat myself in many emails, as I’ve already had people asking, “how we plan to partner / compete with this new service”, as “It will seem to people like direct competition”.
For me the key passage in the launch blog is:
Designed for the Fortune 1000 and the Global 2000, this service is designed to accelerate cloud adoption. It simplifies deployment, migration, and management using automation and machine learning, backed up by a dedicated team of Amazon employees. AWS MS builds on AWS and provides a set of integration points (APIs and a set of CLI tools) for connection to your existing service management system. We’ve been working with a representative set of AWS enterprise customers and partners for the last couple of years in order to make sure that this service meets a very wide range of enterprise requirements.
So:
- It’s for large companies (as SMEs don’t really do ITIL etc.).
- It’s about integration with existing service management via APIs.
- Even though there’s console functionality over the top of the APIs (to provide minimal viable accessibility) this couldn’t displace a service management system entirely.
We have been working with AWS on this, so we’re one of those partners mentioned above. This gives us the services at their end to properly bring AWS into the Integrated Digital Services Management (IDSM) fold. In many cases this is just giving us a uniform way to do something (and have it reported) where there were previously hundreds of different variations on the approach that could be taken (e.g. patch management).
Overall I don’t think this is AWS eating our lunch – it’s AWS making it easier for our customers to use them (and easier and more consistent for us to help them do that).
Original Comments
CN
I was being a bit facetious with the “eating our lunch” comment :-) Perhaps not enough coffee after being stuck trying to get into Chorley after a truck spontaneously combusted on the M6.
Workloads are going to be deployed on AWS/Azure more and more (not so much on Cisco’s InterCloud Services…)
So it’s good to know the answer to “how do you provide operational support. patching etc of workload OS’s in your hybrid solutions?”
is “exactly the same way we do for private cloud/on-premises workloads* “
*from the client/users’ perspective
MH
Re Cisco Interconnect – Article on The Register this morning
Cisco to kill its Intercloud public cloud on March 31, 2017 • The Register
NB
Is CSC part of this also CS?
What’s the Role of AWS Consulting Partners in AWS MS?
‘APN Partners were key in the development of this service, and play an active role in the deployment and use of AWS MS. Having a standard operating environment not only fast tracks customer onboarding, but creates many different opportunities for APN Partners to enable and add value for AWS MS customers. In the coming weeks, we will also be launching a new AWS Managed Services designation as part of the AWS Services Delivery Program for APN Partners (stay tuned to the APN Blog for more information to come).
Key to the integration and deployment of AWS MS, AWS Consulting Partners enable Enterprises to migrate their existing applications to AWS and integrate their on-premises management tools with their cloud deployments. Consulting Partners will also be instrumental in building and managing cloud-based applications for customers running on the infrastructure stacks managed by AWS MS. Onboarding to AWS MS typically requires 8-10 weeks of design/strategy, system/process integration, and initial app migration, all of which can be performed by qualified AWS Consulting Partners. In order to participate, APN Partners will need to complete either the AWS Managed Service Provider Program validation process, and/or earn the Migration or DevOps Competency, as well as complete the specialized AWS MS partner training.’
Introducing AWS Managed Services
CS
Yes – specifically our AWS services under BR
HS
(Since I appear to have been invited to comment)
It’s like in the old days of B2B e-commerce hubs … there was always that ‘on ramp’ work. Some B2B Exchanges made that easy for customers. Other’s did not. The ones that did further cemented their position. The warning for CSC, at the time (mid 90s), was this: We did supply chain consulting, but supply chain became a service (the B2B hubs). Since CSC consulting supply chain practice defined itself as “selling people to do supply chain work” we never got into the game of *being* the B2B hub … even if we did do B2B implementation work. It’s the same with clouds, but on a much larger scale. If we define ourselves, and therefore limit ourselves, in a narrow role, we’ll be like the horse buggy whip makers in the era when the first auto cars were coming in.
It was inevitable that AWS would launch such Managed Services of course. The long long history of ‘cloud impacts on our business’ documented in C3 is a legend in its lifetime. Let’s move on. We cannot remain an infrastructure operations services company, surely? Surely that message is now several years overdue? Surely the declining part of the traditional market is plain to see? Why would anyone be surprised?
Markets evolve like this:
– first Commodities
– then Products
– then Services
– then Experiences
– then Amenities
Make money at one level, and competition eventually pushes you to the next level, where you need to find new blue oceans. So AWS is moving from ‘product’ to ‘service’ in some areas. This might sound theoretical, and it is a broad generalisation, but the commoditization AND servitization (look it up) together combine to cause us to change our offers. It’s like the pet shop that no longer sells pet grooming products but does the pet grooming as a service.
We can keep on trying to hang onto old models, to retain some revenue and opportunity, but the time will come when a complete break must be taken. And one of the best clean break strategies there is is this: *be* the element of transformation. Take the clients on the journey. That’s an ‘experience’ to give them and it often positions yourself for whatever they ask for next.
Had the supply chain consultants at CSC in the mid 90s realised this they would still be here. But they are not. They let a trend destroy them for they defined their role too narrowly. They did not understand that much of what they did could be automated away via the function of the new B2B hubs. As a result, the practice in CSC started to decline. At first they found it harder to find work, which they interpreted as a downturn in the market for their skills, so they did the logical thing, reduced the size of the supply chain practice. Over time, it eroded to very little, a few people hanging on doing some niche work on the edges of the market.
NF
backed up by a dedicated team of Amazon employees
Is this just an additional revenue earner for AWS rather than bringing in their partner network more?
CS
I read that as firstly pandering to a group that expects people to be massaging their egos, but the reality is that they put together a 2pizza to maintain the cohesion of this on top of an ever growing services estate.
So this isn’t the staffed by Amazon help desk.
Filed under: DXC blogs | Leave a Comment
Tags: aws
Originally posted internally 28 Nov 2016:
Background
This is another one of those blog posts where the same question has come up multiple times in the past few weeks, so there’s probably a broader audience for the discussion.
Where do I anchor my trust?
The point of a blockchain is to anchor trust against proof of work (Bitcoin style) or proof of stake (Etherium style) – if you already have a trust anchor then you don’t really need a blockchain. Examples of trust anchors that we frequently do have are TPMs, HSMs and CAs[1] (including Active Directory) – in fact anywhere that there’s an existing identity ecosystem there will be existing trust anchors for that identity ecosystem.
So why all the fuss about Blockchain?
Blockchains seem to be driving a wedge into places where it’s been difficult to federate trust/identity, but I’d suggest that Santander and Goldman Sachs walking away from R3 might at least in part be because they’ve figured out that fancy crypto doesn’t solve political problems.
But I still want a secure audit trail..
Signed audit trails are of course still a good idea, and aren’t anywhere near widely used. The question here is whether the root for that signing needs to be a distributed trust mechanism, or a simple key store.
Note
[1] The public CAs (as trusted by popular web browsers) are right now a total mess. There are far too many examples of negligence and malfeasance. This is in fact one area where Blockchain could be really useful (e.g. for authenticity validation and certificate revocation).
Retrospective
I think people are starting to get the whole trust anchor point here, and the fact that there’s generally little need to establish fresh trust. The conversation seems to be moving on to ‘distributed transaction ledger’, which to be fair to R3 is exactly the language used for the Corda launch.
Tim Bray recently wrote ‘I Don’t Believe in Blockchain‘, which provides further food for thought around the (lack of) geek ecosystem emerging around the technology. That said, some of the smartest people I know are presently beavering away at R3…
Original Comments
MW
You’ve probably seen this CS, interesting insight into government thinking for leveraging distributed ledger technology for delivery of government services, potentially significantly disruptive…..as well as proof of work and proof of stake, they’re arguably harder to compromise versus centralised systems and currency of shared data is assured..
Estonia are leading the way.
Filed under: DXC blogs | Leave a Comment
Tags: Bitcoin, blockchain, DTL, etherium, R3
Bionics – a primer
TL;DR
Greater automation is the future for the IT industry, and we’ve called DXC’s automation programme ‘Bionics’. It’s about being data driven with a flexible tool kit, rather than being all in on a particular vendor or product. To understand what we’re trying to achieve with Bionics (besides reading the rest of this post) I recommend reading The DevOps Handbook, and to get the foundation skills needed to contribute please run through the Infrastructure as Code Boot Camp [DXC only link].
Introduction
‘Bionics’ is the name that we’ve given to DXC Technology’s automation programme that brings together CSC’s ‘Operational Data Mining’ (ODM) and HPE ES’s ‘Project Lambroghini’. This post is written for DXC employees, and some of the links will go behind our federated identity platform, but it’s presented here on a public platform in the interest of ‘outside in'[1] communication that’s inclusive to customers and partners (and anybody else who’s interested in what we’re doing). What I’ll present here is part reading list, and part overview, with the aim of explaining the engineering and cultural foundations to Bionics, and where it’s headed.
Bionics in three words
- Analytics – because we start with data to identify operational constraints.
- Lean – because there’s no point in automating a broken process.
- Automation – through a tool bag approach to apply the right tool to the appropriate situation
Not a vendor choice, not a monoculture
The automation programme I found on joining CSC can best be described as strategy by vendor selection, and as I look across the industry it’s a pretty common anti-pattern[2]. That’s not how we ended up doing things at CSC, and it’s not how we will be working at DXC. Bionics is not a label we’re applying to somebody else’s automation product, or a selection of products that we’ve lashed together. It’s also not about choosing something as a ‘standard’ and then inflicting it on every part of the organisation.
Data driven
Bionics uses data to identify operational constraints, and then further uses data to tell us what to do about those constraints through a cycle of collection, analysis, modelling, hypothesis forming and experimentation. The technology behind Bionics is firstly the implementation of data analysis streams[3] and secondly a tool bag of automation tools and techniques that can be deployed to resolve constraints. I say tools and techniques because many operational problems can’t be fixed purely by throwing technology at them; it’s generally necessary to take an holistic approach across people, process and tools.
Scaleable
The constraints that we find are rarely unique to a given customer (or industry, or region) so one of the advantages we get from the scope and scale of DXC is the ability to redo experiments in other parts of the organisation without starting from scratch. We can pattern match to previous situations and what we learned, and move forward more quickly.
Design for operations
Data driven approaches are fine for improving the existing estate, but what about new stuff? The key here is to take what we’ve learned from the existing estate and make sure those lessons are incorporated into anything new we add (because there’s little that’s more frustrating and expensive than repeating a previous mistake just so that you can repeat the remedy). That’s why we work with our offering families to ensure that so far as possible what we get from them is turnkey on day 1 and integrated into the overall ‘Platform DXC’ service management environment for ongoing operations (day 2+). Of course this all takes a large amount of day 0 effort.
Required reading
What the IT industry presently calls ‘DevOps’ is largely the practices emerging from software as a service (SaaS) and software based services companies that have designed for operations (e.g. Netflix, Uber, Yelp, Amazon etc.). They in turn generally aren’t doing anything that would be surprising to those optimising manufacturing from Deming‘s use Statistical Process Control onwards.
Theory of constraints lies at the heart of the Bionics approach, and that was introduced in Goldratt‘s The Goal, which was recast as an IT story in Gene Kim (et al’s) The Phoenix Project. I’d suggest starting with Kim’s later work in the more prescriptive DevOps Handbook, which is very much a practitioner’s guide (and work back to the earlier stuff if you find it inspiring[4]).

The DevOps handbook does a great job of explaining (with case study references) how to use the ‘3 DevOps ways’ of flow, feedback and continuous learning by experimentation[5].

Next after the DevOps Handbook is Site Reliability Engineering ‘How Google Runs Production Systems’ aka The SRE Book. It does just what it says on the jacket, and explains how Google runs systems at scale, which has brought the concepts and practices of Site Reliability Engineering (SRE) to many other organisations.
Learning the basics of software engineering
The shift to automated operations versus the old ways of eyes on glass, hand on keyboards means that we need to write more code[6]; so that means getting ops people familiar with the practices of software engineering. To that end we have the Infrastructure as Code Boot Camp, which provides introductory material on collaborative source code management (with GitHub), config management (with Ansible) and continuous integration/continuous delivery (CI/CD) (with Jenkins). More material will come to provide greater breadth and depth on those topics, but if you can’t wait check out some of the public Katacoda courses.
Call to action
Read The DevOps Handbook to understand the context, and do the Infrastructure as Code Boot Camp to get foundation skills. You’ll then be ready to start contributing; there’s plenty more reading and learning to do afterwards to level up as a more advanced contributor.
DXC Resources
Some of the books referenced above are available on DXC University e.g. The DevOps Handbook, The Phoenix Project and (not mentioned above) The DevOps Adoption Playbook. Thanks Jeff Ely for the pointers.
Notes
[1] My first ‘outside in’ project here was the DXC Blogs series, where I republished a number of (edited) posts that had previously been internal (as explained in the intro). I’ll refer to some of those past posts specifically.
[2] I’ve been a huge fan of understanding anti-patterns since reading Bruce Tate’s ‘Bitter Java‘. Anti-patterns are just so much less numerous than patterns, and if you can avoid hurting yourself by falling down well understood holes it’s generally pretty easy to reach the intended destination.
[3] It’s crucial to make the differentiation here between streams and lakes. Streams are about working with data now in the present, whilst lakes are about trawling through past data. Lakes and streams both have their uses, and of course we can stream data into a lake, but much of what we’re doing needs to have action in the moment, hence the emphasis on streams.
[4] If you want to go even further back then check out Ian Miell’s Five Books I Advise Every DevOps Engineer to Read
[5] More on this at 3 Ways to Make DXC Better
[6] Code is super important, but it’s of little use if we can’t share and collaborate with it, which is why I encourage you to Write code. Not too much. Mostly docs.
Filed under: DXC | Leave a Comment
Tags: Bionics, DevOps, SRE
Originally posted internally 18 Nov 2016:
Background
Late yesterday I got an email from my colleagues in France asking me to review a pitch deck about our Docker capabilities for a financial services client. I’m repeating my answers here as they probably deserve some broader sharing…
Docker in the Enterprise
Their presentation hit most of Ian Mielle’s Docker in the Enterprise Checklist, which I’ve used with other customers.
The question it left me with is ‘what are they trying to achieve’, by which I mean what is the point of containerising (existing) applications? The entire thing seemed to be aimed at a mass migration exercise – what’s that supposed to accomplish?
Faster testing
For me the point of containerisation is faster cycle time for testing, which is super useful if you can insert containers into a critical bottleneck in the idea->production pipeline where existing tests are too slow. This is particularly the case in development, where containers can help to provide much quicker feedback, and save developers repeating steps that they know work. Of course once a container is the output of a development process it then makes sense to have some means to take containers to production, which then drives the need to provide for a wide variety of operational considerations.
Connecting agile infrastructure to business needs
We shouldn’t make the same mistake we have with cloud where customers have bought a story of agility, agility, agility: agile business needs agile software needs an agile infrastructure. Far too many customer conversations run along the lines of ‘so I bought a cloud to be my agile infrastructure, when do I get my business agility?’. The business agility only happens by providing a connective tissue between business needs and the agile infrastructure. Generally this will take the form of a continuous integration (CI) pipeline, and when we join that to a cloud we have the ability to do continuous delivery (CD)[1].
Containers can help speed up flow and feedback within a CI/CD pipeline, and containers in production can be the new cloud target; but we must help our customers build those pipelines, and not just repackage old apps in new wrapping (because although that might put hours on the clock for us, it doesn’t really provide much value to them).
Other container benefits
I’ll conclude by adding that containers can offer benefits in resource usage (versus VMs) with RAM, CPU and startup time, but those are only achievable in an environment where there’s a good understanding and close control over how shared libraries are used. Containers also provide application portability between environments, but making apps portable before you need to move them is a premature optimisation.
Who’s doing this already?
There was also a question about customer references, so I noted that: In terms of existing customers we have a large OpenShift deployment, but it’s not reference-able (sensitive government account). Most of our other customers are at an exploratory/experimental stage (or using containers just in their ‘mode 2’ division, often with poor consideration for operational issues). I’d also note that most of the quick wins are in the development area.
Note
[1] Where continuous delivery means the ability for any commit that passes tests to be pushed to production. I don’t generally expect our customers (especially those in regulated industries) to be shooting for CD meaning continuous deployment, where every commit that passes tests is pushed directly to production.
Retrospective
This was the blog that got most comments, so I was very pleased to see a lively discussion on the topic, and different areas of the company starting to work together.
Original Comments
CN
So for DevOPs and in particular containers, although the same could be applied to serverless/loosely-coupled apps, use cases are there certain customers or types of customers CSC should be targetting?
I’ve worked on some PoCs and small parts of big orgs may have “a product” and a dev team who are actively developing a software solution that would fit with fast testing cycles, CI and the whole ethos of these new tools. Many others though, some newer, but typically the older, larger, legacy customers, have very large estates where they run legacy apps, some COTS, or where we provide VDI to a large part of their estate and they do not have a focal app that they develop in house. This makes “selling” the idea or benefits of these new tools harder as it is more difficult to demonstrate the tangible benefits, whether it’s directly to the customer, or for our own internal use.
Should we be moving away from big monolithic customers?
Is it simply that in GIS we don’t see the app-side(GBS) as much and some of our bigger customers have huge development farms that we don’t see?
Are we just setting them up servers or storage and never question why or what they wanted it for and we don’t spot the pattern of “5 VMs this week, 5 more next week, then decom them” because we are treating the provisioning/ordering requests in a disconnected way?
Is there room/time/space for the PMs or PE/DEs to look holistically at a request for what is a dev/test environment as you reference above and give architecture the chance or incentive to suggest that rather than just standing up the customer 5 VMs a week ramping up to 200 or rebuilding the same 20 every week, that we could offer them a solution such as the OpenShift one you mentioned, or a VIC deployment?
Lastly would that be frowned upon when it comes to billing? If you sell/bill 200VMs versus 40VMs runnning 5 Docker instances each…how is that efficiency recognised in revenue, e.g. how do we drive the good behaviour and new innovations?
Lots of questions, I know, but I really want to look at some practical implementations, appreciating that some are sensitive, but in particular any innovative uses which aren’t the traditional “We are company X and software is our business so we were already doing Docker/Jenkins etc. can you just sell us VIC/Openshift so we don’t have to build it ourselves?”
AC
CN
Interesting questions too AC
Obviously VMware’s preferred option is to use the lightweight Photon OS as the platform for hosting your containers (possibly circling back to Chris’s earlier post about VIC)
However I have heard a reasonably hard and fast “we only support RHEL” from the cloud delivery org. That in itself is reasonable based on the scaling back we are doing pre-merger. Is there bandwidth for people to cover other non-SOE’d environments. Personally I can’t see why CentOS, Ubuntu and Photon couldn’t be supported, but I’m not aware of any internal training Cloud or Platform engineers have had on supporting Containers.
I know CS and CK devised the Infrastructure-As-Code workshops which have been run multiple times here in Chorley and, I believe, in Chesterfield. That is a great jump-off point for engineers to start thinking about and learning about containers, but most engineers leave that and their day to day work doesn’t utilise that learning.
It’s a wider catch-22 question.
Sales: “Do we support containers, I have a customer that wants them?”
Operations: “We haven’t had any customers that wanted containers before so we aren’t able to support them”
I believe in theory the progression is
1. Identify Market opportunity
2. Specify and design an offering
3. Build that offering
4. Deliver the offering and industrialise/automate the delivery support
5. Provide operational support for the offeringWhere does the training of the delivery/support staff come?
Is it the responsibility of the offering to assign part of it’s development budget to training Operational Engineering (OE) to be able to support the offering?
This has been mentioned on CS/SH PLM/ODF calls recently but I would be interested to see how it’s implemented in practice where sales and customer zero traditionally fund training of staff.
AC
Thanks CN,
I will reach out to our POD’s and service teams to advise on their current capabilities, however I suspect that this time it will pass us by.
CS
A few points from an offerings perspective:
1. We have SOEs for Ubuntu (and OEL and CentOS) in addition to RHEL.
1a. I’m not sure that it makes any sense to bake Docker into the SOEs as it’s too much of a moving target (something that’s been brought up in a rash of ‘Docker’s not ready for production’ blog posts over the past few months).
2. We’ve been working on integration of Agility with Kubernetes (which implies Docker underneath)
3. VMs on a vBlock is still fine, but we’re moving now to Modern Platform, which provides a much more flexible (and lower cost) infrastructure
#2 there is probably the key one in terms of answering the question of what we have from an offering perspective for Docker/containers. Having an offering for Docker itself makes about as much sense as having an offering for ‘ps’ or ‘grep’ or any other user space Unix tool – we need to manage at a higher level, and bringing together our Cloud Management Platform and Kubernetes does that (though it still leaves a bunch of holes to fill with other aspects of service management).
Going back to the original post… anybody who’s buying into a container management solution without thinking about how it connects to their CI to become CD probably hasn’t thought things through completely, and we need to provide more help with that process.
NS
If someone says the only answer is RHEL for the cloud, then talk to someone else as they don’t understand cloud . Take a look at RHEL Atomic and Alpine Linux for some other alternative container OSs. The container OS should be the responsibility of the application developer though and no-one should expect support from the IT support function / CSC IMO.
Running Docker on top of your Linux of choice is fine, but that’s a very limited approach and isn’t suitable for containers in production. For that, as CS mentions, you need a container manager. Agility isn’t there yet and until we can see what it does and what limitations it may have it’s difficult to know whether it will be a great tool or just a tick box. Shout out to the Agility team – share your design plans and get some feedback!
Docker/containers are just one aspect of the emerging cloud native application development/hosting options. If you take into account PaaS and serverless computing paradigms then at present I can’t see how Agility will support this wider capability. Agility + support for containers seems a little like the old argument that if I have a VM and can automatically deploy some middleware on it I have a PaaS platform! I therefore think CSC needs to get a little opinionated in this space and start to think about re-using some of the account knowledge around OpenShift, Cloud Foundry, BlueMix, etc. that is surely out there.
CN
Interesting point about the RACI for the Container OS NS.
I agree everything should be self service and neither the Dev OR CSC should look after container OS…over and above dropping it and spinning up a new one if required, but that “should” all be handled by Agility/Openshift/vRealize/Bluemix….etc.
I know that currently the Agility Devs are focussing on delivering pre-promised road map items and updates/fixes…not sure where Docker integration/management is on their Roadmap.
PC
Hi AC,
Docker containers are also implemented in Windows Server 2016 which is now GA. The features is called Windows Containers. I believe we also have a Windows 2016 SOE that is available. Please reach out to PT for more information.
Here is a great quickstart article: Windows Containers Quick Start
We’ll be looking at Windows Containers for new MyWorkStyle offering deployments, in the new year, so watch this space! :-)
CN
Interesting to hear that PC would be a great Lunch+Learn in AEC or GIS town hall topic. I’d sign up to see that use case!
PC
Thanks for the feedback. My initial thoughts are that containers would help us constrain the sprawl of virtual machine hogs in an environment, helping us to control costs but also better control the predictabilty of resource usage over time. It’s no more than a theory at this stage. We need some lab time to see if it has wings and to truly understand any other benefits. I’m very open to ideas and new ways. :-)
AC
Hi PC,
I think for me its the service, support and availability aspect from an application perspective.
If the Base O/S becomes almost the equivalent of a Hypervisor for the docker layer and it’s component, it is almost a commodity item. (Take it with a grain of salt, but we don’t need to patch monthly, we roll out new VM’s with the pre patched SOE instead.) a standard sized VM with a standard OS spread over multi vblocks or cloud environments, just means far lower support costs for CSC.
It should also mean we have capability to report on performance metrics, not just at the CPU layer, but now, more importantly at the docker, and application layer,
End user experience can be a higher focus. (how long does it really take a user to carry out these tasks, and where is that constraint or bottleneck)
Also improved service for our clients with a higher application uptime far simpler to achieve, and simpler DR scenarios that if not automated, then far swifter to trigger and spin up.
I haven’t even started to dig into the real potential of Client PC docker containers yet. That could be a whole world of fun.
Filed under: Docker, DXC blogs | Leave a Comment
Tags: Docker
Originally posted internally 9 Nov 2016:
TL;DR – the 3 ways
- Improve flow
- Improve feedback
- Improve our ability to learn by experimentation
Why this is for you
When you see the word ‘DevOps’ please keep reading – this post is still for you. I deliberately left the word DevOps out of the title of this post, because I don’t want people to filter based on assumptions. This post is for you.
This post is for you if you’re a developer that doesn’t do ops – because it’s about how we help ourselves and our customers improve development.
This post is for you if you’re and ops person that doesn’t do dev – because it’s about how we help ourselves and our customers improve operations.
This post is for you if you’re a project manager – because it’s about how we make our delivery better.
This post is for you if you’re an architect – because it’s all about design thinking, and how we can make things better by design.
This post is for you if you’re a manager – because your help is needed in leading the necessary changes to our culture – the way we do things around here.
What is DevOps anyway?
DevOps is the set of practices that emerge from organisations that have designed for operations, which is a more mature level of design than design for purpose, or design for manufacture. Pretty much every product or service goes through design evolution, and we can now see many software based services that have effectively designed for operations. DevOps is the label we’ve given to the stuff they’ve done to accomplish that.
What are the ‘3 ways’?
- Flow
- Feedback
- Continuous Learning by Experimentation
The 3 ways originate from the total quality management movement in manufacturing, and over the course of the last few years those lessons from the late 20th century are being relearned and applied to software. They were first articulated in a DevOps context by Gene Kim and his co-authors in The Phoenix Project, and have recently been much more clearly explained in practical terms in The DevOps Handbook.
The rest of this post will look at each of the 3 ways, and what it means to us at DXC
Continuous Learning by Experimentation
The tip of our spear here is Operational Data Mining (ODM), which is run out of GD’s Operations Engineering (OE) team. ODM takes the data from our service management and ancillary systems and allows us to perform analysis, modelling, hypothesis extraction and experiment design for things happening in our delivery.
ODM helps us identify the constraints in our operational environment that are holding us back, and it helps us figure out what to do about them.
Pretty much every experiment we’ve run so far has succeeded, because the data has let us to obvious stuff, and generally it’s clear what to do about it. It’s not uncommon for front line staff to say, ‘I knew that, I knew we needed to do that’. The way we do things around here, our culture, has stopped those front line people from fixing those problems. ODM is providing the empowerment to change how we do things around here, to change our culture (to more data driven decision making rather than decisions made by ‘HiPPOs‘ – the Highest Paid Person’s Opinion).
It’s worth highlighting here that the true measure of ODM working for us will be when we move past the obvious ‘I knew that’ stuff and start finding the real edge of our organisation. We’ll know that’s happening when experiments fail to produce the expected results, and that’s just fine. Learning by failing needs to sit alongside of learning by doing and learning by using in our overall learning approach.
Flow
Flow is about moving things through our ‘factory’ as quickly as possible. It means breaking things down so that they’re smaller, easier to manage, and more likely to succeed.
Flow is the opposite of ‘Death Star’ projects, where every conceivable requirement and every possible risk mitigation gets pushed into something that takes years to deliver and $MMs to get there.
Just about every struggling project that I encounter is one where we’ve piled up a bunch of requirements, and pushed back delivery. Those projects get later and more complex, and more complex and later. We fix that by delivering as little as possible, as early as possible, as quickly as possible – then following with the next incremental delivery.
Feedback
Feedback is about finding out whether something works or not as soon as possible, so that any corrective action can be early and inexpensive.
Practices like continuous integration (CI) improve feedback when developing software, but there are many opportunities to create and improve feedback besides CI.
Feedback can only work if we’re willing to accept that things can go wrong, and be ready and willing to change what we’re doing (a little) and try again.
Many of the customers I talk to expected more from the cloud they bought from us. They bought into ‘agility, agility, agility’ – that business agility needed agile software that needed an agile infrastructure. Having bought the agile infrastructure they waited for the magic to happen, but there is no magic. We need to help those customers create the connective tissue between their business needs and their cloud infrastructure, and that’s done with delivery pipelines. Pipelines that embed testing and quality assurance. Pipelines that provide feedback.
What *you* can do
Think about what you’re doing:
- Does it improve flow?
- Does it improve feedback?
- Does it provide an opportunity for learning by experimentation?
If you can’t answer yes to at least one of those then think again, and ask for help if you’re struggling on your own.
Personal learning
We cant become a learning organisation without individual learning, and we shouldn’t conflate learning with training, or learning with education (as Andrew Clay Shafer explains in his ‘There is No Talent Shortage‘).
IT is a complex space, so nobody comes into an IT career without a desire to learn, but for some of us that desire gets crushed by burnout. An early statement in the DevOps handbook is:
When people are trapped in this downward spiral for years, especially those who are downstream of Development, they often feel stuck in a system that pre-ordains failure and leaves them powerless to change the outcomes. This powerlessness is often followed by burnout, with the associated feelings of fatigue, cynicism, and even hopelessness and despair.
If your work at DXC is making you feel like that then firstly take heart that we’re trying to fix things, and secondly please try to find again that thirst for learning that brought you into an IT career in the first place.
Conclusion
DevOps is just a name that’s been coined for the stuff that organisations that are good at delivery do.
We want to be good at delivery too, which means we need to embrace DevOps.
There are 3 ways: Flow, Feedback and Continuous Learning Through Experimentation – everything that we do should aim to improve at least one of those.
Here’s a nice visual from the folks at Pivotal:
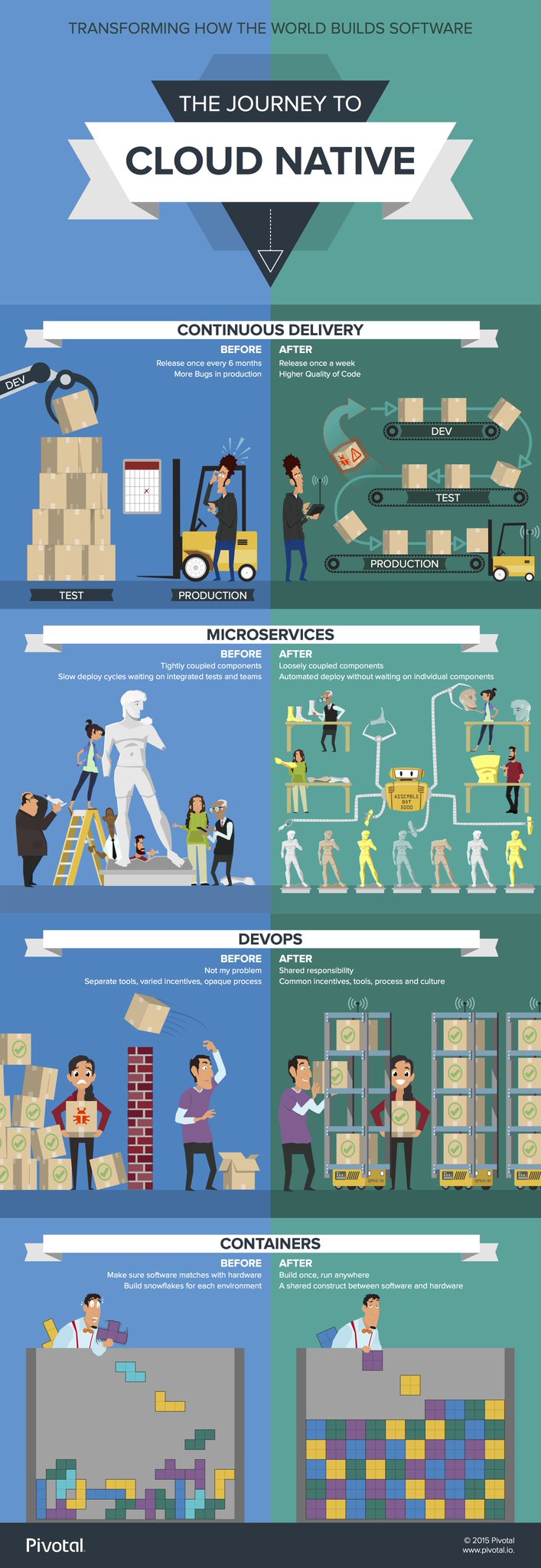
Retrospective
This post more than any from the back catalogue embodies why I took the job in the first place and what I’m trying to achieve. Things don’t change overnight, and the arrival of DXC means that I’ve gone from a ‘bigger train set’ to an environment that’s three times bigger still; but the weekly ODM reviews show the power of incremental gains. If the UK can use incremental gains to come 2nd in the Olympics and Paralympics then we can do the same to come 1st in the global services integrator competitive landscape.
Original Comments
MB
Great post – well done. Having being an advocate Agile + DevOps + Lean Change in Consulting (ANZ) for some time I am totally with you.
The big question is how can this lead to real, tangible action within CSC? That is, what 3 things would you do if you were Steve Hilton, Jim Smith, or Carlos Lopez to foster a culture of Flow, Feedback, and Faith (Trust, Experimentation and Learning)?? I ask because culture is the challenge before anything else.
For me I would:
– Introduce Lean Change techniques into the way we run our business (see Lean Change | CSC Consulting — CSC Consulting Australia and Lean Change: a unique approach to managing change at speed — CSC Consulting) – we use it in our consulting practice
– Foster a culture of trust by setting clear expectations around what is required from employees, THEN remove bureaucracy, approvals, red-tape and THEN manage the exceptions (the 5% who get it wrong not the 95% who get it right)
– Invest in better business intelligence so we all gain more situational awareness which leads to us improving what we do.
Of course I totally understand that it’s not a simple as what I’ve written – the leaders have the tough job of keeping the business running well, while driving change through it – that’s not easy stuff!
CS
Thanks MB – I wasn’t familiar with the Lean Change material, and it’s great stuff.
The good news here is that the process to change our culture is already underway. I should explain that with reference to my preferred definition of culture – ‘the way we do things around here’, and so we’re changing the way we do things around here.
As I mentioned in the post the Operational Data Mining from the Operations Engineering (OE) team is where we’re leading the change, by identifying the constraints then capturing the data, doing the analysis, building the model, forming the hypothesis and running the experiment; rinse and repeat (and share lessons across the org). In recent weeks we (as a management team) have been looking for ways to push that forward (from the Global Delivery Network) into the broader picture of how we engage on delivery.
The bad news is that we have a psychological safety problem that touches many of our people, it’s been a problem for a while, but it’s particularly bad as we head towards DXC. I’m getting the ball rolling now to figure out how we establish better psychological safety for more of our people once we’re past the merger. I don’t think we can do much to foster trust until we’re trustworthy as an organisation – so the first step has to be ‘Make Safety a Prerequisite‘ (if I may borrow from Modern Agile).
The investment in better business intelligence is happening – that’s why we have a data science team in OE, and why we’re working with our colleagues in Big Data & Analytics to build robust and contemporary flow based analytics platforms for the data exhaust generated by our operations.
SS
“- Foster a culture of trust by setting clear expectations around what is required from employees, THEN remove bureaucracy, approvals, red-tape and THEN manage the exceptions (the 5% who get it wrong not the 95% who get it right)”
Makes so much sense as a guiding principle. Hopefully DXC will provide a great opportunity for a clean slate approach rather than a mishmash of legacy thinking and workarounds on top of workarounds…
Filed under: DXC blogs | 1 Comment
Tags: DevOps
The DXC Blogs – Paying for Linux
Originally posted internally 22 Sep 2016, and it’s another post where I took an email reply to a broader audience.
I got an email question about switching from Red Hat Enterprise Linux (RHEL) to Oracle Linux in order to save cost, and I thought the answer would be worth sharing more broadly:
With Linux it’s important to be clear that you’re paying for curation of the distribution, support, and the patches/updates that go with that. Although there is a key used on the OS to provide access to updates, it’s not really a license in the traditional sense.
What Oracle have done is copied the Red Hat Enterprise Linux (RHEL) distribution, and they’re selling a support contract at a lower cost to Red Hat. They’ve also done a pretty good job of making the process of switching from Red Hat’s update infrastructure to their update infrastructure fairly painless – so the in place switch is more than a license key change, but not much more. I’d also not be too bothered about Oracle ramping prices later – firstly switching back would be easy, and secondly Oracle seem much more interested in undermining Red Hat than they are in building their own open source based business.
It’s also important to be clear on what the value proposition of a distribution is, which (beyond support/updates) is generally tied to the certification of third party software that will run on top of it. This is where things get tricky for Oracle Linux, as most software vendors (beside Oracle themselves) certify RHEL but not Oracle. It shouldn’t matter, given that the only change is around where updates get downloaded from, but it’s this sort of petty detail that can cause unnecessary noise and problems when faced with an outage.
Personally I’d question the value of paying for Linux support at all, particularly as paying for Linux often becomes a cost barrier to other changes that would otherwise make sense. When did this customer last have an incident with Red Hat, and how did that work out for them (is the myth of software support at play here)?
If you look at the cloud most people use Ubuntu (without paying Canonical for support) or CentOS (a RHEL like distribution).
I’d also highlight the the Canonical support model is much more cost effective than Red Hat. This is something that I wrote about in ‘Banking on Ubuntu‘ a little while ago after meeting Ubuntu/Canonical founder Mark Shuttleworth.
We have standard operating environments (SOEs) for Ubuntu.
Retrospective
Before moving the infrastructure as code training to Katacoda it was run out of Docker containers on AWS. Since RHEL is the most common Linux in our customer environments I went with a CentOS Amazon Machine Image (AMI )to keep things similar. This was painful, because there are no official public AMIs for CentOS (like there are for Ubuntu), just marketplace AMIs, and if you build an AMI from the marketplace you can’t make it public. I wanted to have public AMIs so that staff could run the training materials in their own AWS accounts, and that initially drove me to the unofficial Bashton CentOS. But I fear there might have been a vulnerability in those AMIs, as any VM left running too long turned into a compromise notification from AWS. Only later did I realise that I could just use AWS Linux, which is also EL/yum flavoured.
I’m still shocked by how many organisations think that (for ‘insert specious regulatory reason’) they must pay for Linux support, and generally in a way that has them coughing up by the socket like the bad ole days of proprietary Unix like SCO.
Original Comments
NS
Paying for Linux support is not a technical decision, but purely a commercial one. In a support contract you have to ask who is ultimately responsible for fixing a bug in the Linux kernel – CSC or a vendor? Are customers happy with a CSC reasonable efforts approach or do they want some certainty? It’s the latter approach that the commercial people often insist upon.
CS
It’s not a black and white question of pay or don’t pay – it’s a question of who do we pay, and how much in order to get the right level of risk mitigation?
NS
It might be an interesting option for some customers if we could offer a global Linux support offering around CentOS and Ubuntu.
Filed under: DXC blogs | 2 Comments
Tags: Linux, RHEL
Originally posted internally 16 Aug 2016:
The title of this post comes from a tweet by Evan Goer I saw last week. It’s derived from Michael Pollan’s statement from In Defence of Food: ‘Eat food. Not too much. Mostly plants.‘
Write code
Just as food fuels our bodies, code fuels our industry. The world is moving to infrastructure as code, which I’ve written about before. I noted yesterday that GE’s CEO Jeff Immelt is quoted as saying ‘We hire 4,000 to 5,000 college grads every year, and whether they join in finance or I.T. or marketing, they’re going to code.’ – so whatever you’re doing it’s likely that you can do it better/faster/cheaper by writing some code, and if you don’t know how to do that it’s never too late to learn.
Not too much
Everything in moderation. Quality beats quantity with code just as it does with food.
Mostly docs
Because people need to understand what the code does, and ‘use the source Luke’ just doesn’t cut it. Good docs give your code the superpower of enabling other people to (re)use it.
Collaborate
Finally share, share, share – put the code and docs on GitHub where your colleagues can find it, use it, improve it.
Retrospective
This was a reminder of my earlier ‘The value of artifacts‘, where I first started banging the drum about the importance of documentation (and samples and examples).
Along with the infrastructure as code Katacoda scenarios I’ve published a screencast on getting set up with Git Bash and Atom, and one of the things I highlight there is Atom’s built in Markdown preview, which is super helpful to anybody writing docs that are going to live in/on GitHub.
Original Comments
GS
This is a simple yet good write up to promote movement from sys admins to sys engineers in the organization.
MN
I believe his point was that people working in fields that use computers (not just Information Technology) will need to understand coding just a little more than they do today.
IP
I think we really need to go for infrastructure as code and start cranking it out but I wonder how long before serverless overtakes.
Incidentally are we building infrastructures as code libraries for our partner’s clouds? Be really something if we one day had them available to clients in a catalogue such that they could build their own CSC supported environment, then just press a button to handover support to an SLA. Too much dream?
MN
I’ve been working a bit with containers and I think there’s some legs to it.
There seems to be a need for a universal mediator or we’re just going to be continually tying together pieces. With SDN, it actually seems like it is getting worse, where vendor specific technology/implementations are driving the need to create zones of intermediary relationships.
Function based serverless looks pretty nifty. It is certainly another tool in the toolbox. I’m not really sure how it differs all that much from container based workload chaining though.
Filed under: code, DXC blogs | 1 Comment
Tags: documentation

