CohesiveFT video overview
For those of you wondering what I do in my day job:
Filed under: cloud, CohesiveFT, security | Leave a Comment
Tags: cloud, networking, security
I don’t need to write extensively here about the dangers of regulatory capture by corporate interests. Larry Lessig already wrote ‘One Way Forward‘, and he does a far better job than I ever could. My friend Robert Dunne recently made an astute observation in the wake of the PRISM scandal:

Access to material from the security services seems to be a feature of being part of the ‘ruling party’, which I’d add to what’s already been articulated by Charles Stross in ‘A Bad Dream – Is the United Kingdom a one party state?’ and Jon Evans with ‘Technology and the Ruling Party‘. I’d guess that access to intelligence reports is something like a drug for those in power[1]. It’s a hard habit to kick, but last week the US Congress had a try at putting the Obama regime on cold turkey with the Amash defence bill amendment.
The vote was pretty close at 217:205, and crossed party lines, which has inspired some deeper digging. It turns out that pro-NSA Congressional voters got twice the defense industry campaign contributions:

So if we accept that the votes were bought then it was remarkably cheap – 217 x ($41,635-$18,765) = $4.963m. Considering what the NSA is throwing around each year that seems like a total bargain – less than $5m in political contributions gets the Beltway bandits a Mulligan any time that they need one.
I’d like to see a more detailed analysis of the Congresscritters involved. Defence contributions is likely just another part of the ‘ruling party’ syndrome. My guess would be that the 217 cross party lines and get greater defence contributions because they’re time seasoned politicos who’ve had plenty of time (and money) to be coaxed away from any ideals they might have once held dear.
Of course things were different on Jimmy Carter’s watch. The US had functioning democracy then and FISA was brought in to protect citizens (without it seems much thought for those to whom the 4th amendment doesn’t apply – of course that was before the US hosted most of the entire planet’s communication infrastructure). What a shame Carter didn’t shore things up with some solid legislation to limit the effects of corporate contributions in politics.
On the bright side the perception of corruption in the US (and UK) is low. That’s what you get when the mass media is bought and paid for by the same people who own the ruling party.
Notes
[1] For a good account of how the SIGINT agency tail started to wag the foreign policy dog I can highly recommend ‘GCHQ‘ by Richard Aldrich.
Filed under: politics | Leave a Comment
Tags: Beltway bandits, bribery, corruption, FISA, Larry Lessig, one way forward, PRISM, regulatory capture, ruling party, SIGINT, spying
The web filter industry
There has been a LOT of noise over the past week about David Cameron’s proposals to have default on web filters for UK ISPs (which seems to be happening despite it not being part of official government policy, and entirely outside of any legislative framework). Claire Perry (Conservative MP for Devizes) has been leading the moral panic, though the meme has been bouncing around Westminster for some time and seems to cross party lines – I once heard Andy Burnham trotting out the same rhetoric (as Secretary of State for Culture, Media and Sport), but luckily nothing was done then. The politicians mostly seem to be responding to calls from the traditional press media (and particularly the Daily Mail) which boil down to:
People are doing things on the Internet that we don’t understand. We don’t like that, so make them stop.
The Open Rights Group (which I regularly donate to) have taken the lead on the fight against this. It’s an important fight, and I’ll do anything in my power to help.
The geek response – it’s somebody else’s problem
A lot of geeks see web filters and other sorts of censorship as the type of damage that the Internet was designed to route around.
Yes, people will use VPNs. Some might even follow my guide for setting up your own (which you can run free in the cloud).
Yes, people will use proxies. Some might even follow my guide for using EC2 as a web proxy.
It’s true that the filters will be trivial to circumvent, and that the knowledge to do that is reasonably widespread.
The problem – this blog will get classified as ‘web blocking circumvention tools’ and nothing I write here will be visible to the passive majority who’ll remain sat behind their filters.
Life behind the wall
I spent a little over a decade working for firms that imposed web filters, so I know what it’s like, how counter-productive it is and how to tunnel through.
I’ve seen the false positives, and fought through the exception processes.
The bottom line here is that China is pretty much the only place that runs things for itself. Everywhere else gets its lists of what’s good and what’s bad from the same handful of (US) security firms. Their biggest customers (and certainly those driving the most restrictive rules) tend to be oppressive Middle Eastern regimes.
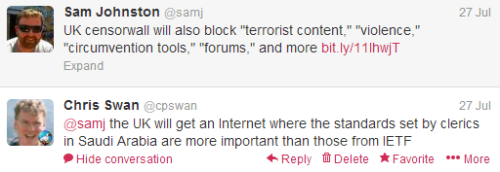
It’s not just the filter rules that get imported
One of my favourite authors, Charles Stross, pointed to an interesting article this morning:

An important subtext in the article led to this brief Twitter conversation:

So the moral crusade seems to boil down to this…
We should import the moral values of Saudi Arabia, because that’s somehow better than the moral values of the United States.
Though of course it’s never described like that. It’s always ‘think of the children’.
The industry itself
This isn’t one of those times where I smell the whiff of corporate corruption in the halls of Whitehall. Web filtering is a few $M pimple on the behind of the multi $B global security industry. You don’t need to spend too long behind the curtain to find that pretty much everything is farmed out to bots with precious little human involvement. When you do get a human involved it quickly becomes clear who calls the shots – if Bahrain wants something on the list it stays on the list. I’ve usually found it easier to get the list source to deal with false positives (Bahrain requests notwithstanding) than to get local exceptions on corporate filters. I’d expect that dealing with ISPs will be much harder – they don’t want to do filtering in the first place, and won’t want to spend any more on running costly exception processes. Our web liberty is on the market to the lowest bidder.
Conclusion
I usually try to be optimistic – to see the use of technology as a driver towards utopia, but this time around I’ll leave the final words to my dystopian friend Robert Dunne:
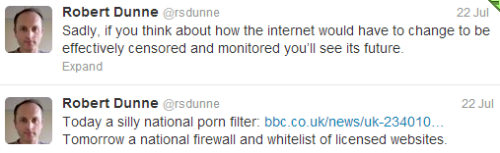
When they flick the switch look for me on the darknet.
Filed under: politics | Leave a Comment
Tags: censorship, filter, moral panic, morals, open rights group, proxy, vpn, web
Your own VPN in the cloud
Last week I saw that major credit card companies are blocking payments to VPN services:

This is bad news if you want to protect your stuff online (or pretend that you’re in another country).
One way to deal with this is to run your own VPN service in the cloud. This is of course of little use for anonymity, as the cloud IP can be traced back to a subscriber account, but it’s just fine for protecting yourself from any man in the middle between coffee shop or airport WiFi and the services you’re using.
I’ve written before about using Amazon EC2 as a web proxy, but this time around I’m going to cover setting up a full VPN.
OpenVPN
There are many types of VPN out there – L2TP, IPsec, PPTP etc.
![]()
Many of the popular VPN services offer OpenVPN because it’s relatively easy to use (and often works when various filtering schemes block other VPN types). I used OpenVPN for years to avoid filters on employee WiFi.
OpenVPN has a good range of client support, and I’ve personally used it on Windows, Linux, Mac, iOS and Android.
Cloud or VPS?
This post is about running a VPN in the cloud, but it would be remiss of me to not mention virtual private servers (VPS). For most of my own VPN needs I use VPS machines – they’re cheaper than cloud IaaS (if you’re not benefiting from a free trial), and you get a substantial dollop of bundled bandwidth. LowEndBox is usually a great place to start shopping, and I’ve had good experiences with BuyVM in the US and LoveVPS in the UK[1]. Whether you use a VPS or Cloud machine it’s also possible that you might use the machine (and its bandwidth) for other stuff – like hosting a web site.
The following examples are based on Amazon’s EC2 service, and use t1.micro instances. If you’re new to AWS (or set up a new account with a fresh credit card) then you can get a year of free tier, which includes t1.micro instances for Linux (and Windows). Free tier also includes 15GB of bandwidth[2].
Option 1 – OpenVPN Acess Server
The server product from the OpenVPN guys is called Access Server, and it’s available as a software package, a virtual appliance or a cloud machine. In the past I’ve mostly used the software package on my VPS machines and Ubuntu instances in EC2, but given the title of this post I’m going to focus on using the cloud machine.
There’s an illustrated guide for using the AWS console to launch a cloud machine, but some of the info there seems a little out of date. To keep things really simple I’m going to try to illustrate how to launch a machine with a single line:
$EC2_HOME/bin/ec2-run-instances ami-20d9a449 –instance-type t1.micro –region us-east-1 –key yourkey -g default -f ovpn_params
This uses a file ‘ovpn_params’ containing something like:
admin_pw=pa55Word
reroute_gw=1
reroute_dns=1
You will of course have to have sourced an appropriate creds file e.g.:
export EC2_HOME=~/ec2-api-tools-1.6.7.2
export JAVA_HOME=/usr
export AWS_ACCESS_KEY=your_access_key
export AWS_SECRET_KEY=your_secret_key
export AWS_URL=https://ec2.us-east-1.amazonaws.com
Obviously you’ll need to put in the right paths and keys to suit your account and where you’ve installed the EC2 tools.
Make sure that the security group used (default in this case) has TCP port 443 open to where you’re using it from (or 0.0.0.0/0 if you want to use from anywhere) and then sign in to the console at https://your_ec2_machine_address using the address from the EC2 console (or ec2-describe-instances). Once signed into the console you’ll be offered the chance to download a client, and the client can then be connected using the same credentials (e.g. username:openvpn password:pa55Word).
Option 2 – CohesiveFT VNS3 free edition
Disclaimer – I work for CohesiveFT, and getting free edition available in AWS Marketplace was one of the first things I pushed for when I joined the company.
OpenVPN Access Server is limited to two simultaneous connections unless you buy a license. If you want some more connections then VNS3 free edition offers 5 ‘client packs’.
I’ve previously done a step by step guide to getting started with VNS3 Free edition, which goes through every click on the AWS Marketplace and EC2 admin console. Once you’ve been through the Marketplace steps it’s also possible to launch it from the command line:
$EC2_HOME/bin/ec2-run-instances ami-dd7303b4 –instance-type t1.micro –region us-east-1 –key yourkey -g vnscubed-mgr
In this case I’ve got an EC2 security group called ‘vnscubed-mgr’ set up with access to TCP:8000 (for the admin console) and UDP:1194 (for OpenVPN clients).
VNS3 is designed for creating a cloud overlay network rather than being an on the road VPN solution, so there are a few different things about it:
- No TCP:443 connectivity – unlike Access Server it’s not configured to listen on the standard SSL port, which means that you need to connect over UDP:1194 (which may be blocked in some filtered environments)
- Reroute for default gateway and DNS (the stuff that those reroute_gw=1 and reroute_dns=1 options do above) can’t be set. This problem can be worked around easily if you use the Viscosity client on the Mac, as that has a simple check box to set the VPN tunnel as a default route, but it’s more of an issue on other platforms where you need to add the following line to the client pack file:
redirect-gateway def1
- To forward packets from VNS3 back out to the Internet it needs to be configured to do NAT. For the default 172.31.1.0 network put the following line into the Firewall config box (and ‘Save and activate’):
-o eth0 -s 172.31.1.0/24 -j MASQUERADE
Conclusion
If you want to keep your traffic secure (or access location locked services) then running your own VPN server has some drawbacks in terms of ultimate privacy, but it’s easy and cheap.
Notes
[1] Since Amazon doesn’t have a presence in the UK a VPS is a good choice for watching BBC iPlayer (and other UK locked content) over a VPN.
[2] This is a lot more generous than many VPN services, but if you’re moving around a lot of video it may not be enough. If you go over 15GB then Amazon charges for bandwidth are quite steep, and it may be cheaper to switch to a VPS with a more generous bandwidth bundle.
Filed under: cloud, CohesiveFT, howto | 3 Comments
Tags: Access Server, android, cloud, iOS, iPad, iphone, Linux, MAC, OpenVPN, VNS3, vpn, VPS, Windows
Green Earl Grey
A few years ago I accidentally gave up coffee. It wasn’t pleasant at the time, but I felt much better afterwards, so I stuck with it. I still enjoy a very occasional double espresso, and caffeine is a wonderful thing when it’s not part of a regular habit or dependency.
When I returned from the holiday that led to me giving up coffee Twinings had just launched their new range of Green Teas, and frequently gave away samples at London Bridge and Canary Wharf stations – so some mornings I got two samples. I quickly discovered that a cup of green tea made for a good start for the day. The pineapple and grapefruit mix was an early favourite, but then I discovered the Green and Earl Grey and I had a new daily cuppa.

Initially I had no problem getting this blend, as the launch promotion reached into most major supermarkets and I could pick it up off the shelf. Then I found myself having to make a special trip to the big Tesco in the next town, and then I found myself having to order direct from the Twinings online store. I used to order a lot in one go (normally the best part of a years supply) in order to get free shipping.
To my horror I discovered earlier this year that Twinings had discontinued the line (not long after I’d made my last order). I wish they’d emailed to say so in advance – I’d have probably bought a huge stockpile – tea doesn’t seem to go off.
Whilst I kept hoping to stumble across a hidden away stash my supplies dwindled, and I found myself trying out alternatives…
Green on its own is too boring.
A bit of green and a bit of Earl Grey in the same cup comes out with too much black tea flavour.
I even tried flavouring some green tea bags with Bergamot oil following some instructions I found on Reddit, but it came out with too much of a bitter after taste.
and then I found my salvation.

Taylors of Harrogate (the tea brand that goes with the famous Betty’s tea rooms that was a fixture of my University days in York) has a Green Earl Grey blend.
It’s a bit more floral than the Twinings, and I suspect it’s a bit more sensitive to water temperature (add some cold first to avoid bitter after taste), but after about a month I’m happily switched over.
Fingers crossed that they’re still doing it when I finish the 350 bags I got in my first order.
Filed under: review, wibble | Leave a Comment
Tags: Bergamot, Bettys, Earl Grey, green, Taylors, tea, Twinings
Review – BeagleBone Black
I first came across the BeagleBone when Roger Monk presented at OSHUG #18 in April 2012. It was easy at the time to write it off as too expensive and too underpowered – the Raspberry Pi was finally shipping and the lucky first 2000 already had their $35 computers whilst the rest of us waited for the next batch to roll out of the factories. Who in their right minds would spend three times more on something less capable?

Things change quickly in the tech world, and the BeagleBone Black seems to have resolved issues with both price and capability. It’s impossible to avoid comparisons with the Raspberry Pi, so I won’t even try:
| Raspberry Pi Model B | BeagleBone Black | |
| MSRP | $35 | $45 |
| I paid | £23.39 | £25.08 |
| Processor | 700Mhz ARMv6 | 1Ghz ARMv7-A |
| RAM | 512MB SDRAM | 512MB DDR3 |
| Onboard flash | None | 2GB |
| External flash | SD | microSD |
| Network | 100Mb | 100Mb |
| USB ports | 2 | 1* |
| Video out | HDMI/Composite | microHDMI |
| Audio out | HDMI/3.5mm | microHDMI |
| Resolution | 1920×1080 | 1280×1024 |
| GPIO ports | 17 | 65 |
The comparison could go on further, but I’ll try to concentrate on the main differences…
CPU
The BeagleBone Black’s CPU is faster by clock speed and a more modern design. This means that it can run Ubuntu rather than needing it’s own flavour of Linux. That probably isn’t much of a big deal now that Raspbian is so popular, and it’s a rare day when I notice I’m using Raspbian rather than Ubuntu (in fact Raspbian feels more like Ubuntu than Debian for the tools I regularly use).
BeagleBone Black 1 : Raspberry Pi 0
Storage
The BeagleBone comes with 2GB of onboard flash, which means that there’s no need to buy an SD card to get it going. Better still it comes pre installed with Angstrom Linux, a web IDE and a node.js environment for controlling GPIO. There’s further expansion via microSD and given that there’s little spread on price or performance these days between SD and microSD that’s a good thing as the form factor is tidier.
BeagleBone Black 2 : Raspberry Pi 0
Video
Eben Upton often talks about the Raspberry Pi using a mobile phone system on chip (SOC), but I suspect that it might actually be a part designed for set top boxes (there are after all very few mobile phones with full HD screens). Not only can the Pi drive a screen at 1920×1080, but it also has hardware acceleration for popular video CODECs. The original BeagleBone was missing video altogether (it needed a ‘cape’), so it’s a big move forward that the Black can drive a screen, and 1280×1024 is fine for many purposes – it just doesn’t suit modern wide screen monitors, and it’s not much use for home entertainment purposes.
BeagleBone Black 2 : Raspberry Pi 1
USB
The twin USB port on the raspberry Pi means that it’s easy to connect a keyboard and mouse, or a keymote and a WiFi dongle. I know that many people use their Pis with (powered) USB hubs, but I so far seem to have got away without needing to do that. Sadly the BeagleBone Black has only 1 USB port, so it’s pretty hard to use USB peripherals without resorting to a hub. Given that there’s an Ethernet connector that’s the same height as a double USB port at the other end of the board it seems rather silly to have cut this corner.
BeagleBone Black 2 : Raspberry Pi 2
The BeagleBone Black has some other USB tricks up its sleeve though… Like the Raspberry Pi it takes power from a USB connector (mini rather than micro), but unlike the Pi it’s designed to connect to another computer (as the power draw is within normal USB range). In addition to using this port for power the BeagleBone can also use it as a virtual network port, so all that’s needed to start playing with the BeagleBone is what comes in the box and a regular laptop or computer.
BeagleBone Black 3 : Raspberry Pi 2
GPIO
Not long after my kids first got their hands on a Pi I realised that they weren’t interested in low powered computers (they already have better) or cheap computers (they don’t pay for them). They were however interested in physical compute projects – anything that could interact with the outside world… and that meant doing stuff with general purpose input output (GPIO).
We’ve had lots of fun flashing LEDs, building burglar alarms and playing ladder game, and all this stuff was made possible by the Pi’s GPIO. I’ve not yet exhausted the Pi’s GPIO capabilities with any project, but it wouldn’t be too hard – though there’s always I2C and SPI there to expand things. I’ve also found it reasonably easy to work with breadboard projects using a ‘Pi Cobbler‘ or build my own things using boards like Ciseco’s ‘Slice of Pi‘.
The Pi might be good for GPIO, but the BeagleBone is great for it. With 65 GPIO ports, and nice chunky ports down both sides (perfect for poking components or jump wires straight in).
BeagleBone Black 4 : Raspberry Pi 2
Projects
I thought I’d reflect back over the projects that I’ve used my Pis for over the past year or so:
- OpenELEC (living room media streaming) – whilst I expect it wouldn’t be too hard to port OpenELEC to the BeagleBone Black it’s weaker graphics capabilities mean that I can’t really see the point.
- iPad connectivity – the BeagleBone would be just fine at running VNC.
- Securely accessing your home network – the key requirements here are SSH and low power consumption, so the BeagleBone Black is great.
- Alarm – the better GPIO on the BeagleBone would have made this very easy (and possibly it could have all been done in the integrated IDE).
- Arcade Gaming – porting MAME should be straightforward. The video limitations won’t matter for older games, and the better CPU might make some games work better that struggle on the Pi. Hooking up a joystick via GPIO should be easy.
- Project boards – there’s less need for project boards with BeagleBoard given it’s better GPIO capabilities, and the stackable ‘capes’ offer lots of very tidy ways to expand.
- Sous Vide – this would be an easy project on the BeagleBoard, though I ended up using a Model A Raspberry Pi for this (which would still be a bit cheaper).
Conclusion
For me the Raspberry Pi has excelled at two things:
- It’s a great low cost streaming media player when paired with OpenELEC (or similar XBMC distro)
- It’s great for physical compute projects
The BeagleBone Black doesn’t have the media capabilities of the Pi, but it’s even better that the Pi for physical compute projects. Despite that I’d be surprised if the BeagleBone enjoys the same success in terms of community mind share and volume shipped. Of course that doesn’t matter… the improvement of the Black over the original BeagleBone shows that we can expect a much better/cheaper Raspberry Pi some time in the not too distant future.
Filed under: BeagleBone, Raspberry Pi, review | 3 Comments
Tags: BeagleBone, BeagleBone Black, comparison, GPIO, physical compute, projects, Raspberry Pi, raspbian, review, Ubuntu
Shiva Iyer at Packt Publishing kindly sent me a review copy of Instant OpenELEC Starter. It’s an ebook with a list price of £5.99, and I was able to download .pdf and .mobi versions (with an .epub option too). It’s also available from Amazon as a paperback (£12.99) and for Kindle (£6.17).

The book is pretty short, with a table of contents that runs to 35 pages, and it’s set at an introductory level that seems intended for new users of OpenELEC and XBMC.
It breaks down roughly into thirds:
- Installation (with instructions for PC and Raspberry Pi).
- Managing XBMC – the basics of creating content libraries for various media.
- Top 10 features – some slightly more advanced customisations.
If you’re after a detailed explanation of what OpenELEC is, and how it’s put together then you’ll need to look elsewhere.
I could pick holes in some of the details of the Raspberry Pi install guide, but the information is accurate enough. Overall the author, Mikkel Viager, has done a good job of explaining what’s required and how to do things.
Filed under: Raspberry Pi, review | Leave a Comment
Tags: ebook, openelec, Raspberry Pi, Raspi, review, RPi, XBMC
A well regulated lobby
Our elected (and unelected) officials keep getting caught with their hands in the till by investigative journalists.

The proposed remedy for this is to establish a register for lobbyists. A plan that the Chartered Institute of Public Relations (CIPR) seems to be eagerly embracing (when it’s not saying that the plan needs to be even more encompassing). I smell a rat. It’s just not normal for people to ask for more regulation of their industry, unless they have (or are trying to establish) regulatory capture.
Why politicians like the idea
A register of lobbyists will make it easy for politicians to check the credentials of those they’re speaking to. This will make it harder (more expensive and time consuming) for investigative journalists to pose as lobbyists. Newspapers are now going to have to run cut out lobby organisations (on a variety of issues to suit the needs of future stings). This will likely preclude public interest broadcasters like the BBC from participation – building fake lobby organisations won’t be seen as a good use of TV license payer’s money.
So this is all about stopping politicians from getting caught, and does nothing to stop politicians from being corrupt (and of course even the non corrupt politicians don’t like people getting caught, because it makes their parties and the entire political establishment look bad).
Why the professional lobbyists like the idea
A register will be a barrier to entry. Their job is to gain access to people with limited time and bandwidth, so anything that cuts down the size of the field helps.
Why ordinary citizens should not like the idea
If the only lobbyists are professional lobbyists then our political system becomes entirely bought and paid for[1]. Amateur lobbyists and pressure groups are an essential part of the democratic process. As Tim Wu pointed out in his ORGCon keynote at the weekend – movements start with the amateurs and enthusiasts.
I was personally involved in the creation of The Coalition For a Digital Economy (Coadec) at a time when the Digital Economy Bill (now Act) was threatening to undermine the use of the Internet by many small businesses. That organisation is now well enough established that I’m sure it could step in line with any regulation of lobbyists. It’s hard to see how we’d have got from a bunch of geeks in a Holborn pub to what’s there today without the support of friendly politicians. We needed access, and regulation would be just another barrier to that access.
Conclusion
Regulating lobbyists will not prevent corruption in politics. Quite the opposite – it will make it more challenging for individual corruption to be found out, and strengthen the systemic corruption of corporate interests in politics. We all ought to get lobbying about this while we still can.
Notes
[1] Rather than mostly bought an paid for as it is today.
Filed under: politics | Leave a Comment
Tags: citizen, corruption, lobby, politician, politics, regulation
Indistinguishable from fraud
I came across this tweet yesterday:

It was timely, as I was in the midst of sorting out a foreign exchange transaction that had gone wrong. I’d sent $250 to a recipient in the US, and only $230 had shown up in their account (and then their bank had charged them $12 for the privilege of receiving it). Somehow $20 had gone missing along the way.
The payments company had this to say on the matter:
I would also not be happy if $20 was missing from a transfer and I apologise for the situation.
This does, unfortunately, happen from time to time. Normally it is a corresponding bank charge charged en route, which we will refund.
I responded:
Whilst your explanation might fit something off the beaten path there’s no good reason for $20 to vanish into the ether on a well worn road like GBP/USD. My first guess would be somebody fat fingered this at some manual data entry stage (I’d like to hope that you have a straight through process, but I expect it isn’t), my second guess would be fraud.
and they’d said in return:
I assure you that our instruction was for the full amount and there is no fraudulent activity.
At the moment our payments to the USA are via the SWIFT network and as they are international cross border payments there can be correspondent banks involved that we have no control over.
So there we have it – some random correspondent bank along the payment chain treating itself to $20 is completely fine – that’s not fraud. Or maybe two banks helped themselves to $10 each? Nobody seem to know, and nobody seems to care – cost of doing business.
I wouldn’t call out international payments and foreign exchange (FX) as being ‘advanced financial instruments’, but I do know that it’s mostly a disgraceful shambles. If I add up the total fees, charges and spreads associated with this simple transaction then it comes out at almost $50, or around 20% of my transaction. That’s just utterly ridiculous for squirting a few bits from a computer in the UK to a computer in the US. It makes what the telcos charge for SMS seem reasonable (which it is not).
It’s no wonder that developing economies, and particularly small firms within developing economies, are struggling to engage in international commerce. If it’s this hard and expensive to move money along what should be the trunk road of UK/US then I dread to think what it’s like trying to do business off the beaten path (such as to or from Sub-Saharan Africa). I’m pleased to see that the World Bank is doing something about this by investing in payments companies that route around some of the greedy mouths to feed by taking advantage of low cost national payments networks (like ACH in the US, Faster Payments in the UK and corresponding systems elsewhere). Of course SWIFT still gets their pound of flesh (for the time being), but perhaps as we get better netting over that network the toll will be minimised.
Filed under: could_do_better, grumble | 3 Comments
Tags: banking, charges, fees, financial services, fraud, FX, international, payments, spreads
OpenELEC dev builds
Over the past week or so my automated build engine for OpenELEC on the Raspberry Pi hasn’t been working. XBMC has grown to a point where it will no longer build on a machine with 1GB RAM.
![]()
Normal services has now been resumed, as the good people at GreenQloud kindly increased my VM from t1.milli (1 CPU 1GB RAM) to m1.small (2 CPUs 2GB RAM). In fact I’m hoping that the extra CPU might even make the build process quicker. I have to congratulate the GreenQloud team for how easy the upgrade process was – about 3 clicks followed by a reboot of the VM. Not only are they the most environmentally friendly Infrastructure as a Service (IaaS), but also one of the easiest to use – thanks guys.
Filed under: cloud, Raspberry Pi | Leave a Comment
Tags: cloud, GreenQloud, iaas, openelec, Raspberry Pi, Raspi, RPi, XBMC

